
This Week’s AI Weekly Summary (Rumors of Microsoft Scaling Back Investments, and What Investments by Chinese Big Tech Mean, etc.)
Let’s reconsider the rumor that struck fear into everyone.

Before proceeding with the text, it is hereby disclosed that this document is an English translation of a report from Korea’s Mirae Asset Securities
(1) Microsoft Investment Reduction?
The ripple effects from Microsoft CEO Satya Nadella—who once stood at the forefront of the AI arms race—seem to have delivered a shock to the stock market. On February 20, Nadella appeared on the renowned podcast “Dwarkesh” and spent over an hour sharing his thoughts on AI and AGI. Among all his remarks, the term “overbuild” triggered a tremendous allergic reaction among investors.
He even personally mentioned that the situation was similar to the “dot-com bubble,” using language that instilled a sense of caution in his listeners. Moreover, he noted that “currently, AGI is still a long way off, and he prefers leasing rather than building data centers.” Taken at face value, this might make it seem as though Nadella has become somewhat of a skeptic regarding AI.
Then, on the very next day—the 21st—TD Cowen released a report stating that “Microsoft is reducing its investment in data centers.” Investors quickly drew their conclusions:
“Satya Nadella has said that AI is overbuilt, and as a result, Microsoft is now pulling back its betting chips.”

Summary of TD Cowen’s Channel Check Report:
1. Canceled U.S. leases amounting to “hundreds of MW” with at least two private data center operators (employing the same strategy that Meta used in 2022).
2. Scaled back the lease conversion of Statements of Qualifications (SOQs, a form of data center leasing intent document)—where previously nearly 100% of submitted SOQs would convert to lease agreements, this trend has recently changed.
3. Reallocated significant overseas spending to the United States by, for example, abandoning contracted land in at least five major markets.
In particular, as seen in the decision to halt construction on the Wisconsin data center (intended to support OpenAI), TD Cowen noted that Microsoft may be holding excess data center capacity compared to its own forecasts. In blunt terms, TD Cowen’s analysis suggests that the CapEx bubble—which had required injecting up to $500 billion in new growth capital over 3–4 years to keep pace with the exponential curve of AI demand—has just burst.
(2) Fact & Vibe Check
If all these conclusions prove true, this would be an issue on a completely different level than the shocks from DeepSeek’s V3 and R1. It’s such a big issue that it would render the “Jebens Paradox” (which helped avert the January fallout from DeepSeek) merely trivial. If one of the industry’s largest infrastructure consumers, Microsoft, starts reducing its investments, other big tech companies are likely to follow suit. This would raise doubts about the trajectory of AI workloads and lead to lower valuations across all AI companies. In fact, after the publication of TD Cowen’s report, stocks related to European energy and U.S. AI infrastructure plunged sharply, and the market experienced a rapid sell-off.
However, Microsoft quickly stepped in to smooth things over by issuing the following official statement to calm those alarmed:
• “There is no change to our data center strategy. We will continue to invest based on a 10‑year outlook for cloud and AI demand. We will adjust regional forecasts upward or downward based on local priorities, but overall investment will continue to increase.”
• “We expect the balance between AI supply and demand to improve by the end of the current fiscal year. In the future, supply will rise to match demand, moving away from the current shortage.”
• “We remain committed to spending over $80 billion on infrastructure in the current fiscal year.”
Moreover, regarding the TD Cowen report on the Wisconsin data center contract, a closer look at the context reveals a different interpretation. Notably, there were no penalty costs associated with the contract cancellation, and the project in question had already suffered “serious delays” related to power supply and facility construction. Given that speed is critical in scaling—as evidenced by the progress of xAI’s Grok 3—this can be seen as part of a restructuring and streamlining of investment execution.
Still, as market sentiment shows, once a seed of doubt is sown, it isn’t easily uprooted. In such circumstances, investors might feel it’s time to pause and truly consider Satya Nadella’s underlying intent. What exactly did he mean by “overbuild”? If it were truly a matter of overinvestment, why invoke something like the “Jebens Paradox” in the first place? Is all of this just a case of “liars’ poker”?
The best way to understand the subtext behind someone’s words is simply to listen to what they say. For instance, as recently as December, Nadella remarked, “I hardly agree with claims that we have reached the limits of AI development. There is much debate over whether we have hit a ceiling in the scaling laws. Rather, we are witnessing the emergence of a new scaling law in Test-Time Computing.” This implies that AI development will continue through the discovery of new scaling laws, which will require even more computing power and energy. Furthermore, considering that in October Nadella stated, “In the paradigm of scaling laws, the new currency is tokens per watt,” the point is even more reinforced.
(3) Microsoft’s Long-Term Vision for the AI Business
Another intriguing aspect of Satya Nadella’s recent comments was his reference to AGI and GDP. This was especially interesting given that it came right after Elon Musk’s xAI Grok outperformed OpenAI to become the world’s most intelligent model.
Nadella conveyed that the AGI race should not be viewed merely as a numerical contest among language models. The key point isn’t that AI’s mathematical, engineering, or coding capabilities are unimportant, but rather that we should only call it the AGI era when AI begins to solve real-world problems and significantly improve human lives.
Furthermore, he believes we are on the cusp of a “new industrial revolution” driven by AI-led, massive productivity improvements that could spur over 10% GDP growth. Just a few days ago, Nadella tweeted about this vision, and even Elon Musk responded in agreement.
The potential example of AGI that Nadella cited was AI’s impact on agriculture in India. The agricultural innovation he mentioned—using AI technology—demonstrates how real-life problems can be solved and productivity improved.
It involves providing small-scale farmers, who suffer from climate change and pest infestations, with advanced data collection systems and a cloud-based integrated platform. Data collected from various sensors and imagery is analyzed, then translated into practical guidelines that are easily understood by farmers through a mobile application available in the local language. This enables them to know precisely when and what agricultural tasks to perform, resulting in significantly increased crop yields, improved quality, and reduced usage of water and fertilizers.
This approach not only bridges the digital divide—by granting small farmers the same data access as large agricultural enterprises—but also presents the possibility of a new agricultural revolution that greatly boosts productivity. In other words, eliminating the global “AI Divide” in access to AI technology is essential for achieving double-digit GDP growth, with the added value from such innovations eventually accruing to those who drive them. Once again, Satya Nadella comes off more as a businessman than a researcher.
Of course, for such a future to materialize, AI would need to be applied across virtually every domain—essentially proving the “Jebens Paradox.” The more broadly intelligence is utilized, the more value can be created that was previously unattainable, so what appears as overbuild can actually be seen as a form of preemptive investment.
Moreover, for scenarios like the agricultural example in India to play out globally, AI models must be deployed much more densely. Additionally, the role of business intelligence—dealing with “heterogeneous data collection, processing, and analysis”—will expand when combined with generative AI.
Therefore, one can infer that Microsoft will intensify its efforts to maintain leadership in traditional SaaS and PaaS enterprise solutions, without ever losing sight of its core business. Unlike the research-oriented approach of OpenAI, Microsoft seems focused on demonstrating the commercial value of AI technology by emphasizing “real revenue.” This focus likely stems from the reasons discussed above.
As AI competition becomes increasingly fierce and the AGI era rapidly approaches, Microsoft’s ultimate task will be to deploy and absorb computing power as a cloud service provider (CSP)—in other words, to “scale.” Nadella’s references to overinvestment and the dot-com era may well be an allusion to the historical rhythm in which even the dot-com bubble eventually gave rise to internet giants like Amazon and Google.
2. The Geopolitical Chessboard of AI Hegemony and NVIDIA
(1) Europe Begins Full-Scale AI Investment
After DeepSeek threw down the gauntlet to OpenAI, our team stated that the Sputnik moment for AI had arrived. This is gradually becoming a reality. Even in Europe—which had appeared to lag behind the U.S. and China—there are continuous reports regarding the securing of computing resources. According to CBRE, Europe could add 937 MW of data center capacity by 2025, a 43% increase over the 655 MW installed in 2024. In addition, the AI cloud computing startup Fluidstack has raised $200 million to expand its operations and plans to build AI data centers worth €10 billion in France by 2026, primarily powered by nuclear energy. Although the momentum has somewhat softened, Europe—a key player on the geopolitical chessboard—is gradually awakening. This appears to be a ripple effect from the upheaval caused by DeepSeek, and it is likely to continue expanding, as it aligns naturally with the concept of sovereign AI.
(2) Apple’s Largest Investment Ever
Apple, a big tech company that had also seemed relatively passive, surprised everyone with a major announcement. The company plans to invest $500 billion in the U.S. over the next four years—its largest spending commitment ever. This investment includes the construction of an AI server manufacturing facility covering 250,000 square feet in Houston, Texas, shifting production of servers previously manufactured overseas to the United States. This facility is being built in collaboration with Foxconn, is scheduled to open in 2026, and is expected to produce servers supporting Apple Intelligence (likely M5 or above). Additionally, Apple has announced plans to invest billions of dollars in advanced silicon production at its TSMCC plant in Arizona.
It is worth noting that during Trump’s first term, Apple had promised to invest $350 billion over five years, leading some to speculate that this new commitment is of a similar scale. Moreover, during the Biden administration in 2021, there was an announcement of a $430 billion investment plan over five years. Viewed from this perspective, the $500 billion commitment can be seen as an extension or repackaging of these previous spending patterns.
On an annual basis, however, the investments increased from approximately $70 billion during Trump’s term and $86 billion during Biden’s term to about $125 billion now—roughly a 50% increase. Furthermore, the decision to build an AI server factory in Texas, emphasizing the “manufacturing” aspect long championed by Trump, is a key point. Concrete new initiatives—such as increasing advanced manufacturing funds to $10 billion—set this investment plan apart from earlier ones. Although Apple had not traditionally favored “getting its hands dirty” in manufacturing, this move can also be interpreted as a determined effort to ensure that Apple Intelligence is not merely used as a launchpad for ChatGPT, meaning that the majority of requests from iPhone users will be processed entirely on its own servers.
(3) Alibaba’s Largest Investment Ever
An even more direct and startling announcement came from China’s big tech. Alibaba revealed plans to invest at least 380 billion yuan (approximately $53 billion) in AI and cloud infrastructure over the next three years—a sum greater than what it has spent over the past decade.
According to Alibaba Group’s own definition, AGI is “an artificial intelligence system capable of performing more than 80% of human capabilities.” This definition not only covers repetitive mechanical tasks in the traditional sense, but also includes complex decision-making, creative thinking, and the integration of diverse knowledge areas. At a February 2025 earnings call, Alibaba Group CEO Woo Yongming even suggested that the AGI industry could become the largest economic sector in the world. This is in the same vein as Microsoft CEO Satya Nadella’s proposal that “the success of achieving AGI should boost global economic growth rates to as high as 10% annually.”
• AGI Economic Scale = Global GDP × 50% (labor expenditure ratio) × 80% (substitution rate) = 40% of global GDP
In other words, since 50% of the current global GDP is directly derived from labor wage expenditures (encompassing both mental and physical labor), the core value of AGI lies in its ability to restructure this economic foundation by substituting for or assisting human labor.
1. Automation of Physical Labor: In sectors such as manufacturing and logistics, AGI-based robotic systems can enable fully unmanned operations through real-time environmental recognition and adaptive decision-making. For example, Alibaba Cloud’s intelligent warehouse system has improved sorting efficiency by 300% and reduced labor demand by 70%.
2. Enhancement of Mental Labor: In specialized areas like financial analysis and legal documentation, AGI demonstrates pattern recognition and logical reasoning capabilities—already sufficient to replace entry-level workers. Internal tests at Alibaba have shown that an AGI system can complete financial report analysis in just 1/20th of the time taken by a human team, with an error rate reduced to below 0.3%.
Thus, Alibaba has made the realization of AGI its top strategic priority, anticipating that its commercial value will exceed the combined value of all current applications. Woo Yongming compared the cloud computing network to an “electric grid” and AGI to the “electricity” transmitted through that grid, implying that only a densely interconnected grid can usher in the AGI era—highlighting the centrality of infrastructure. Both Satya Nadella, Woo Yongming, and various CSPs share a similar mindset, often summarized as “Hyperscale as Moat.”
(4) Huawei’s Onslaught
Another Chinese tech giant making headlines is Huawei. It is no exaggeration to say that Huawei is leading China’s AI technology in every aspect—from fundamental AI model research to AI chip design. If Huawei were a publicly traded company, its stock price would directly reflect Chinese investors’ sentiment on AI.
The breaking news concerns the increased production volume of Huawei’s AI accelerator, the Ascend 910 series. For reference, the Ascend lineup comprises Huawei’s AI accelerator chips, designed to replace GPUs and primarily used for AI and deep learning workloads. Owing to a surge in demand for AI chips, Huawei is now prioritizing Ascend chip production over its Kirin chips.
• Ascend 910: The initial model released in 2019, manufactured using TSMC’s N7+ process (7 nm with EUV).
• Ascend 910B: The second-generation model released in 2022, boasting a unique architecture unlike GPUs or TPUs. It is manufactured using SMIC’s N+1 process, with yields exceeding 60% last year. Some tests claim it delivers 20% higher efficiency than NVIDIA’s A100.
• Ascend 910C: The latest model, released in October 2024, targeting performance comparable to NVIDIA’s H100. Some analysts predict that the Ascend 910C will outperform NVIDIA’s B20 chip—which is being developed for the Chinese market—potentially using SMIC’s advanced N+2 (7 nm) process. Huawei has claimed to have developed 7 nm process technology without EUV equipment. ByteDance, Baidu, and China Mobile have already entered early purchase discussions, with initial orders exceeding 70,000 units.
According to the Financial Times, Huawei has reportedly raised the “yield” of its Ascend 910C production line to about 40%, enabling the line to achieve profitability for the first time—a key news point. This yield is double what it was a year ago (around 20%), and Huawei aims to further increase yields to 60% to meet industry standards. For context, even TSMC’s H100—produced by the world’s leading foundry—has a yield of about 60%.
Note: For the Ascend 910B, based on a die size of 665.61 mm² and a 300 mm wafer, the number of good dies ranges between 50 and 80, yielding approximately 47% to 75% yield.
It was assessed that China had narrowed the gap with TSMC in semiconductor manufacturing process technology by about three years in the latter half of last year, and if Huawei’s current claims are accurate, those figures become understandable. Notably, despite being subject to U.S. export controls, Huawei’s efforts are supported by the Chinese Communist Party, with Beijing encouraging domestic companies to switch from NVIDIA’s dominant chips to Huawei’s AI products. Of course, Huawei still faces the challenge of convincing customers to abandon NVIDIA’s superior CUDA software, and it must overcome issues—such as inter-chip connectivity and memory limitations—that plagued the Ascend 910B. Huawei’s efforts to replace CUDA have been previously discussed in AI Weekly.
Nevertheless, through the close cooperation between state and industry in China, Huawei has established a strong position in the AI inference chip market, controlling over 75% of AI chip production in China. According to a recent FT report, on the production front, Huawei plans to produce 100,000 units of the Ascend 910C processors and 300,000 units of the 910B chips this year. Given Huawei’s claims that the Ascend 910C is comparable to NVIDIA’s H100 and the 910B is roughly equivalent to the A100, these production numbers translate to an H100-equivalent output of about 200,000 units per year. Moreover, the total number of Ascend 910B units already deployed across China is estimated at around 600,000.
Summing these figures, it amounts to roughly 400,000 H100-equivalent units. If all Ascend chips were concentrated in a single cluster, it would represent a significantly threatening amount of computing power to the United States. Of course, achieving such distributed training interconnectivity is extremely challenging in practice. As Anthropic CEO Dario Amodei once remarked, “Isn’t it true that there are still no data centers built with Ascend chips?”
Regardless, from the perspective of the United States—watching China’s aggressive progress—this is a matter of serious concern. The claims by xAI’s Colossus and OpenAI’s Stargate to deploy over one million GPU clusters are certainly not exaggerated. Notably, xAI has amazed the world with its rapid scaling, and on February 26, Jensen Huang publicly stated during an earnings call that “GB200 is being used to train and perform inference for the next generation Grok model.”
(5) Paradigm Shift in AI Models and GPUs
Meanwhile, from the perspective of China’s big tech and hyperscalers, they cannot simply wait for Huawei’s chip supply. Instead, they are expected to feel an increasingly severe thirst for computing power. Consequently, Chinese tech companies are actively turning to NVIDIA—six well-informed sources have confirmed that they are increasing orders for NVIDIA’s H20 chips. Intriguingly, this trend is partly driven by DeepSeek.
DeepSeek, which stunned the world with its “R1,” is now accelerating the launch of its successor. According to three insiders, while the R2 was originally planned for early May, there is now an urgent desire to release it as soon as possible. Transitioning from R1 to R2 naturally requires scaling up reinforcement learning to generate more high-quality synthetic data, which in turn increases GPU demand.
Furthermore, not only does the scaling of reinforcement learning contribute to rising GPU demand, but inference scaling is also a significant factor. In other words, when DeepSeek R1—designed to generate chain-of-thought (CoT) processes—is rolled out to the public, it will inevitably require an enormous amount of computing power.
For instance, even though Meta’s Llama 3 (which is not a reasoning model) used 16,000 GPUs during training, Meta currently operates over 400,000 GPUs for its inference services. Naturally, as a reasoning model, R1 is expected to face even greater challenges.
In response, NVIDIA’s CFO stated during an earnings call on February 26 that “inference AI requires 100 times more computing power than one-shot prompt-based models.” This emphasizes that reasoning models demand significantly more computing power than non-reasoning models that deliver one-shot answers.
On the same occasion, Jensen Huang even remarked that as AI advances, this demand could expand by thousands of times—hence the introduction of the Blackwell architecture.
Our team clearly stated in last January’s AI Weekly that “the advent of DeepSeek R1 will create a massive surge in inference computing demand for GPUs.” With Chinese companies also entering this new scaling paradigm, the global transition towards this model is accelerating with the success of R1.
Furthermore, because inference computing is still in the early stages of its S-curve of technological innovation, competition among companies is expected to intensify even further. In fact, it already has: earlier this month, Google released Gemini 2.0 Pro; shortly thereafter, xAI launched Grok 3—hailing it as the world’s most intelligent; and a few days later, Anthropic released Claude 3.7 Sonnet, earning accolades for its superior coding abilities. There is even speculation that OpenAI will launch GPT-4.5 this weekend. Ultimately, the chaotic race to secure superior intelligence boils down to a competition in computing expansion.
Therefore, it is evident that Alibaba, Tencent, and ByteDance—backed by the Chinese Communist Party and quickly adopting DeepSeek’s models—will also pursue computing resource acquisition with utmost seriousness. In fact, there are reports that they are increasing orders for NVIDIA H20 GPUs. The H20 is a GPU model newly developed by NVIDIA for the Chinese market, with restricted FLOPs, as the H800 will be banned from 2024 onward. This model is far more suitable for inference tasks rather than for AI training.
Although the surge in H20 orders has partly been attributed to DeepSeek, it is also believed that “hoarding demand”—fueled by concerns over stricter semiconductor controls during the Trump administration—is another significant factor. Such demand in China reinforces NVIDIA’s market dominance and helps alleviate concerns that DeepSeek might lead to a decrease in AI chip demand.
(6) NVIDIA’s Moat? Ultimately, It’s Software Capability
The question now arises: how long will GPUs remain the dominant solution? Will other NPUs—such as Huawei’s Ascend—or ASIC chips from American companies like Cerebras, or even those developed by big tech firms, soon become mainstream?
While the overall market size will undoubtedly grow, simply having to hand over dominance to another player poses a significant concern for investors in NVIDIA.
However, NVIDIA has produced empirical results that seem to dispel such worries. Using its TensorRT library, NVIDIA announced tremendous optimizations for DeepSeek R1.
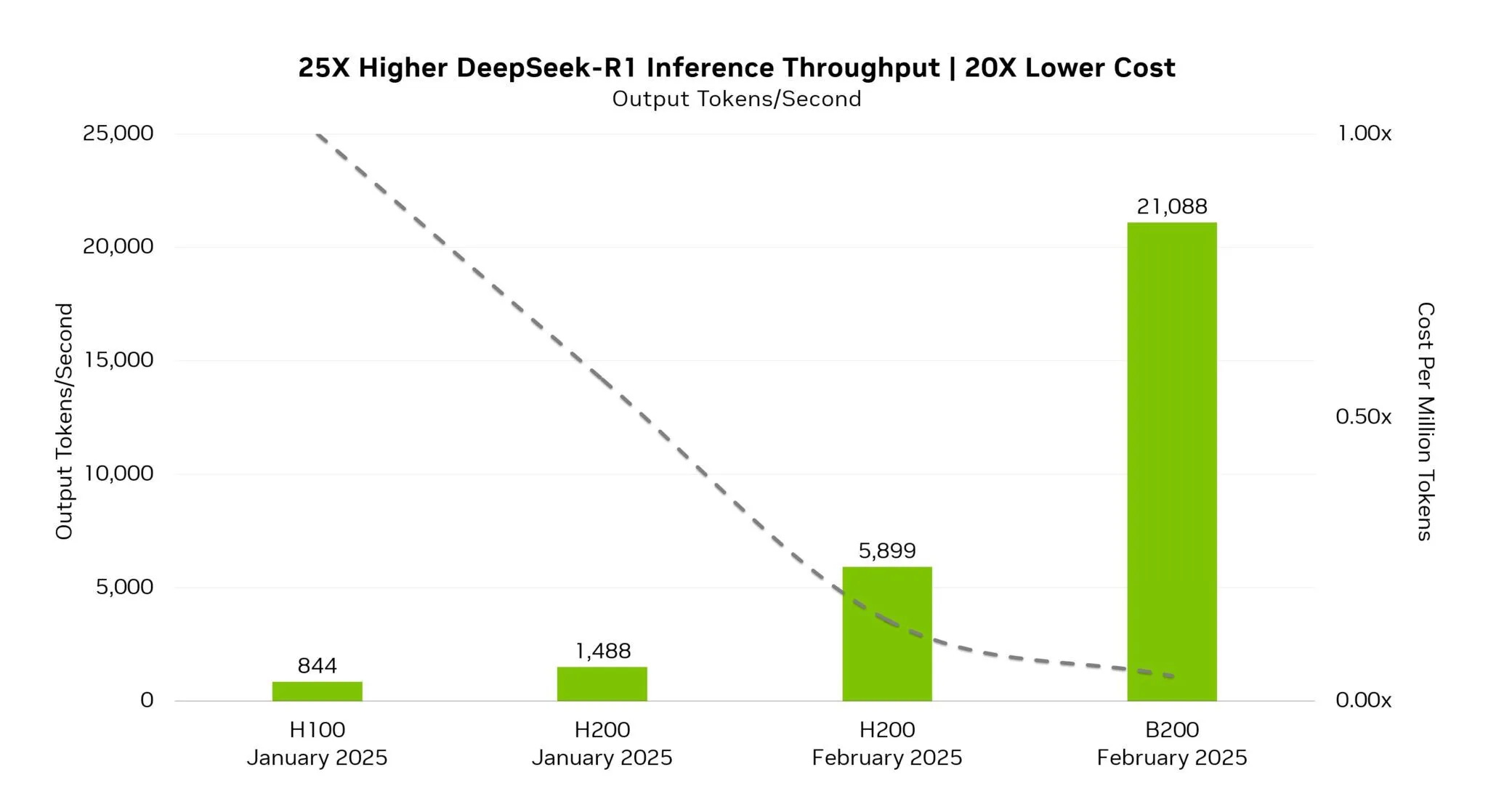
TensorRT is a high-performance deep learning inference optimization library designed to accelerate the inference speed of deep learning models. By utilizing TensorRT to optimize DeepSeek R1 and testing its inference performance, the following results were observed:
According to the graph, the B200 achieved approximately 25 times higher inference throughput than the H100 (from last month). The token generation rate surged from 844 tokens per second to 21,088 tokens per second. In addition, the “cost per million tokens” (depicted by a dotted line) decreased by 20 times—a particularly striking achievement.
Critics may argue that these performance metrics, based on 4-bit floating-point precision, are not entirely meaningful. However, NVIDIA claimed that even after reducing precision to FP4, its performance in MMLU benchmarks is 99.8% of that achieved with FP8 precision. This indicates that, despite the reduced precision, the actual performance degradation of the model is minimal—a testament to the high level of mixed precision optimization achieved by TensorRT.
More importantly, existing GPUs can “evolve dynamically” in performance. Through CUDA-based innovations, NVIDIA has even encroached on the efficiency domain once held by AI accelerator companies like Cerebras or Groq. As shown in [Figure 9], for example, Cerebras claimed that its DeepSeekR1-Distill-Llama-70B model could generate over 1,500 tokens per second, but NVIDIA’s software optimizations completely undercut that claim. During the same earnings call, NVIDIA’s Jensen Huang stated:
“Our architecture is versatile.
Whether it’s an autoregressive model, a diffusion model, or a multimodal model, GPUs excel in all of these areas.
Designing a chip does not guarantee that it will be deployed.
Deploying a new processor in an AI factory is not an easy task.
Although many AI chips are designed, when the decisive moment comes, a business decision must be made to choose GPUs.”
It is important to recognize that NVIDIA is not merely a hardware company—it is also a software company. TensorRT, after all, is a high-level library built atop CUDA, and it is NVIDIA’s software capability that further enhances the cost-effectiveness of its GPU-based solutions, thereby strengthening its moat.
This is precisely why AI developers continue to emphasize that building a software ecosystem is far more challenging than manufacturing chips.
Furthermore, NVIDIA has made this optimized DeepSeek checkpoint available on Hugging Face for anyone to use. NVIDIA is clearly the company most eager to see the widespread adoption of efficient models like DeepSeek’s, because they firmly believe in what is known as Jebens’ Paradox. Remember, only the AI accelerators they develop—from the Blackwell architecture onward—were originally designed with inference computing in mind.