
Samsung Securities - Misunderstandings and the Essence of the DeepSeek Incident
Is the decline due to DeepSeek justified?

This post is a translation of Samsung Securities’ Tech Overweight report into English.
DeepSeek Isn’t Actually That Special
DeepSeek is a good model, but not a particularly extraordinary one.
To understand the market correction said to be driven by “DeepSeek,” one must first analyze whether the DeepSeek AI model is truly special. The DeepSeek V3 and R1 models are indeed good, but they are not exceptionally groundbreaking.
Technical Aspects
1. Achieving recursive performance improvements for R1Zero through reinforcement learning (RL)
2. Employing a multi-stage reward-based RL strategy that includes cold-start fine-tuning
3. Applying GRPO (Group Relative Policy Optimization) to pursue efficiency
These are noteworthy points from a technical perspective.
However, the model merely twists and turns to find a breakthrough in overcoming the constraints of semiconductor restrictions; it does not definitively outperform others. The tools for lightweight design and efficiency used in the DeepSeek model—such as distillation, MoE (Mixture of Experts) structures, MLA (Multi-head Latent Attention), and quantization—have long been a persistent direction in the field.
It is hard to describe DeepSeek as a hidden secret or game-changer from China, as these are strategies also used by U.S. companies. They have gained increased importance and attention for the purpose of scaling up reasoning.
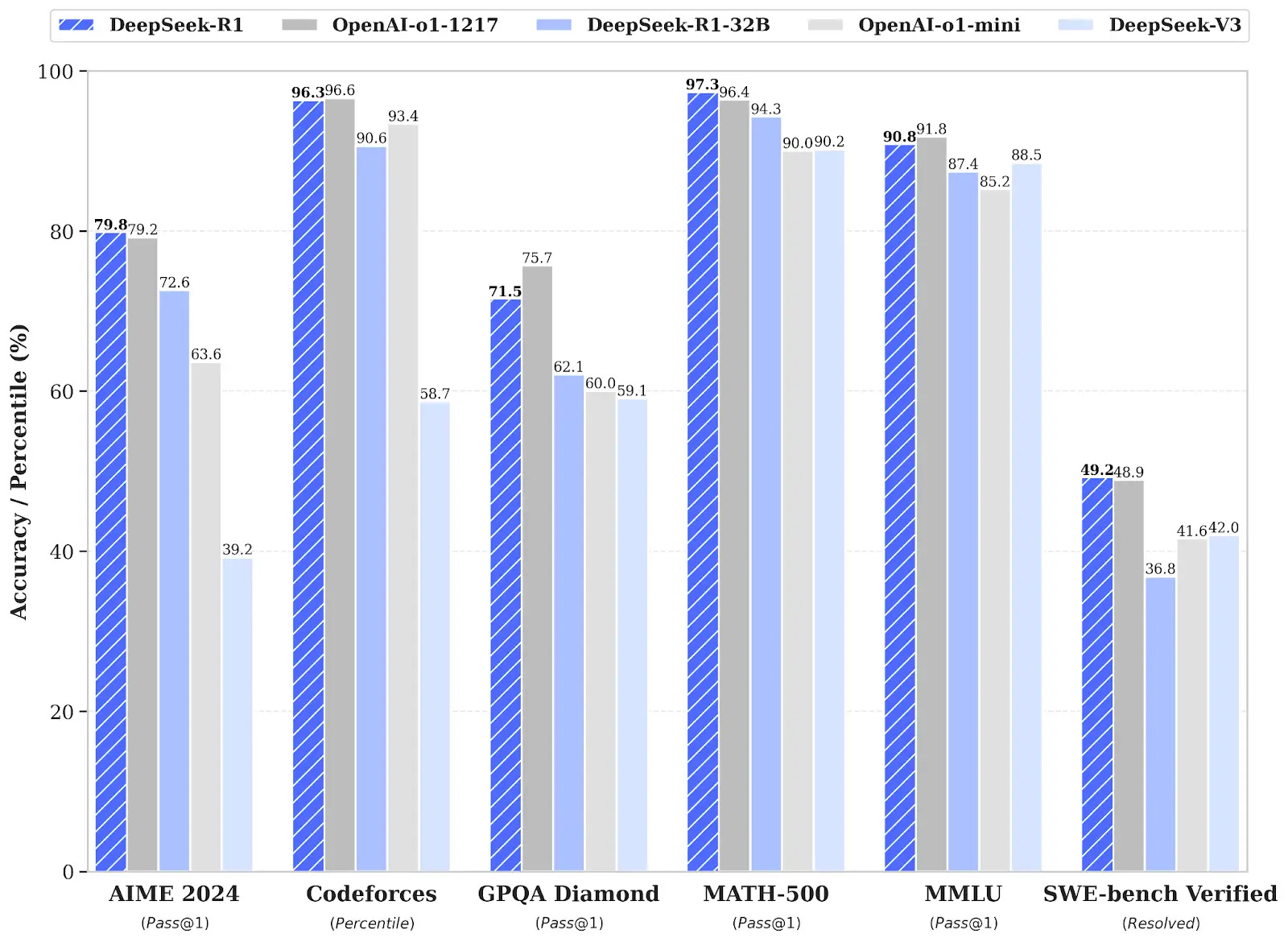
DeepSeek’s Costs Have Been Misrepresented
On the cost side, the low training cost of the V3 model and the low inference cost of R1 have drawn attention. The publicly cited training cost for the V3 model is around USD 5.57 million, estimated by factoring in the hourly rental cost (S2) for 2,048 H800 GPUs running for 2.8 million hours. However, as noted in the paper, this figure does not include expenses for prior research, experimentation, architecture development, algorithm design, and data preparation. Significant costs were also likely incurred in developing R1 based on the V3 model. Reinforcement learning is not dramatically cheaper in terms of compute compared to supervised learning, and the R1 model uses both RL and supervised learning.
R1 touts an even cheaper API price, but you can’t measure inference service costs by API price alone, because each company implements its own monetization strategy differently. In fact, if Google’s Gemini 2.0 Flash Thinking model is priced the same as 1.5 Flash, it may offer a better price-performance ratio than R1. Furthermore, while MoE structures can be efficient in principle because only a portion of parameters is activated, actual inference often involves complex requests and the distribution of tasks across GPUs, which can be relatively inefficient in practice.
Although DeepSeek claims to be “GPU poor,” several industry insiders allege that it possesses around 50,000 Hopper GPUs (mostly H20 and H800, with some H100s mixed in). There’s little reason not to use available resources. Dylan Patel of SemiAnalysis has estimated that DeepSeek may have spent more than USD 500 million on GPUs.
Additionally, rumors suggest that DeepSeek rapidly closed its technology gap by using frontier models from OpenAI and others in its own model development. Both Microsoft and OpenAI are said to be examining these claims.
It’s impossible to prevent leading models from becoming roadmaps for followers. However, when a foundation model underpins a follower, there is an inherent limit to surpassing the original model’s performance.
Investors Suspect a Monopoly Strategy Among U.S. Big Tech in AI
The reason for concern is not about technology, but about the AI “moat.”
It becomes clear from the timeline that the market correction said to have been driven by DeepSeek is not fundamentally a technological issue. DeepSeek V3 was unveiled on December 26 of last year, and R1 on January 20 of this year—there is a lag between these releases and the subsequent market downturn. The panic in the stock market attributed to DeepSeek actually began with media reports that took technical issues and expanded them into political ones. Rather than simply being about technological innovation or the risk of falling behind, it appears to reflect intense worries over whether the United States is implementing its “moat” strategy to maintain dominance in AI.
The statement “A Chinese AI startup has caught up with OpenAI in spite of U.S. semiconductor constraints by innovating algorithms, achieving similar performance at a much lower cost” is not incorrect, but one should be cautious about over-interpreting its implications. In fact, U.S. frontier AI companies could utilize China’s breakthroughs to further widen the gap. We are seeing a positive feedback loop in which inference models are used to create new datasets for next-generation models, and these next-generation models are then used to develop more advanced inference models. This increases the need for computing resources to build advanced frontier models beyond what currently exists. Though China’s counteroffensive has sparked some doubt about the solidity of U.S. Big Tech’s AI monopoly strategy, the battle for AI goes well beyond establishing a “Level 1” model and ultimately aims for Artificial Superintelligence (ASI).
Concerns About U.S. AI Entry Barriers and Lower Semiconductor Investment
1. Doubts About LLM Barriers to Entry:
There is suspicion about the “moat” of U.S. AI. The prevailing assumption was that training models on a larger scale with massive investments in semiconductors created a high barrier to entry. But now, do latecomers have access to models that can be built with less capital, essentially open to anyone?
2. Fears That Cloud Providers Might Reduce Capex:
This leads to skepticism about future semiconductor growth. Were cloud companies squandering money by investing heavily in model scale-ups? As they start focusing on efficiency, might they reduce orders for Nvidia and other semiconductor manufacturers?
3. The Rise of Chinese AI:
Some fear that, having trusted in a U.S.-led AI monopoly and invested heavily in American companies, they could now be overtaken by more efficient Chinese AI.
In contrast, this current market correction does not appear to be driven by genuine technological innovation from China that could overwhelm U.S. Big Tech or emerging startups, nor does it indicate that Chinese Large Language Model (LLM) technology is on the verge of surpassing the United States. The key point is LLM efficiency.
Here is a concise summary of these risks:
1. We do not believe that the barriers to entry for LLMs have been broken.
The lightweight and efficiency-oriented techniques used in the DeepSeek model are industry-wide trends that U.S. companies already employ, and DeepSeek has not actually reduced costs much more than rival models.
2. This event will likely expand AI interest from training to inference, possibly leading to even higher Capex investments by Big Tech.
Far from causing them to slash their budgets, the situation might prompt them to invest more.
3. Although regulations will likely intensify with the rise of Chinese AI, we also expect this will spark a new wave of competitive investment.
In conclusion, although this might look risky at first glance, a deeper consideration reveals it to be merely a brief event illustrating one aspect of AI’s growth trajectory.
Cost Reduction Is the Mother of Increased Demand
Why a Drop in API Prices Does Not Mean Lower Demand for Cloud Infrastructure
Over the past three years, the cost of inference has fallen by around 1,000 times. The essence of the AI services market’s emergence lies in “Q increases as P decreases.” DeepSeek merely accelerated this trend. This is naturally good news for cloud providers, as the rise in API usage (Q) more than offsets the drop in API prices (P).
In fact, since the start of the “A cycle,” the operating margins of the three hyperscalers’ cloud businesses have consistently expanded. In particular, inference is known to offer a better token-margin profile compared to training (estimated at about 50–70%). If it’s that profitable, there’s no reason to hesitate to invest. This is why companies like Microsoft (expected to invest USD 80 billion in FY25) and Meta Platforms (USD 60–65 billion in FY25) continue to raise their capex guidance.
Yann LeCun, head of AI at Meta Platforms, made it clear (likely in response to the DeepSeek situation) that his company’s large-scale infrastructure investment is focused on inference rather than training. Microsoft, which initially led the “Stargate initiative,” has now taken a step back to emphasize technical support—a move seemingly aimed at concentrating on inference infrastructure. Implicitly, it’s suggesting that achieving AGI, which requires higher risk and relies heavily on training infrastructure, be left primarily to OpenAI.
Does This Spell Trouble for OpenAI?
So is the emergence of DeepSeek necessarily bad news for OpenAI? It’s not great news, but it’s not a major blow either. As lightweighting techniques advance, companies equipped with high-performance, large-scale base models and the infrastructure to run them become all the more dominant. Introducing new algorithmic methods also involves trial and error, so having stable, large-scale infrastructure remains an advantage for incumbent leaders.
Ultimately, DeepSeck is also a product that builds upon existing technology. The real crisis for OpenAI would come if a top-tier model appeared that surpasses OpenAI’s latest Model 03. Merely launching a cost-effective model isn’t enough to declare a threat to top-tier enterprises. Instead, this may increase anxiety among second-tier companies that find themselves in a murky middle ground—or those like Meta that aim to expand an ecosystem using a similar open-source strategy. Indeed, news that Meta Platforms has been operating no fewer than four “war rooms” since DeepSeck’s debut appears to stem from this very concern.
The DeepSeek Shock Will Paradoxically Spur Further Demand
DeepSeek’s impact has heightened interest in AI models that can run at low cost.
We are about to see an intensive uptick in AI models made lighter through techniques like distillation and quantization. Instead of worrying that this will reduce cloud providers’ capex, we expect the growth rate of cloud services to accelerate due to new AI-related demand. Even lightweight AI models still need to carry out inference processes (scaling for reasoning) or handle large-scale usage (scaling for inference), making economies of scale in AI datacenters a significant barrier to entry. For most businesses, lower costs reduce the hesitancy to adopt AI models, and software companies will now more aggressively develop AI with similar performance at lower semiconductor costs.
Microsoft CEO Satya Nadella referenced “Jevons’ Paradox” on his X account while discussing DeepSeek’s impact. In the 19th century, it was expected that improved steam-engine efficiency would reduce coal consumption. However, because steam engines became more widespread, coal usage actually went up, as identified by Jevons’ research. Similarly, an increase in AI model efficiency can actually lead to expanded demand for both AI models and semiconductors.
We, too, believe that increasing AI efficiency will lead to rising demand. For Jevons’ Paradox to apply, three conditions generally need to be met, and we believe this case satisfies them.
1. High Price Elasticity of Demand: In our CES2025 report dated January 14, we noted that investment costs for deploying AI services as a business remain prohibitively high. In other words, cost is currently the biggest barrier to increased demand for AI.
2. Large TAM (Target Available Market): Today’s AI has two major TAM drivers—Reasoning scaling and Physical AI scaling. Price declines will trigger latent demand.
3. Feasibility of Supply Expansion: Like in coal mining, AI requires sufficient investment to meet increasing demand.
Are AI Semiconductors Facing a Major Crisis?
The AI Accelerator Cycle Is Not Over
DeepSeek’s notably low development costs and inexpensive service have raised doubts about the demand and utility of AI infrastructure, especially AI semiconductors. However, we believe this concern is overblown, and the market’s reaction has been excessive.
AI model performance is determined by the volume and quality of training data, model parameters, and computing power. From a data perspective, training is expanding beyond text to include images, video, and more. Ongoing efforts to scale computing power for efficiently supporting these data types imply a growing need for high-quality AI semiconductors, where “high-quality” includes both peak performance and efficiency.
NVIDIA’s technology will likely become even more essential in the pursuit of greater efficiency. Unlike OpenAI, which uses FP16 (Floating Point 16), DeepSeek V3 was trained using FP8. Lower floating-point precision has both advantages and disadvantages: compressing data can boost computation speed but comes at the cost of lower precision. Recently, however, FP8 training has gained favor because, in certain stages, cost savings outweigh the downsides of reduced precision. The trend is moving toward FP8—and even FP4—for efficiency. DeepSeek’s efficiency hinges on reducing computation costs while minimizing performance sacrifices. Yet, paradoxically, FP8 and FP4 training is most efficient on next-generation GPUs. NVIDIA’s product roadmap aligns with these emerging trends in AI model development. Starting with the Hopper architecture, NVIDIA began supporting dynamic FP8/16 conversion and optimization at the software level through its Transformer Engine. With Blackwell, FP8 and FP4 are now natively optimized in hardware. Blackwell FP4, for example, achieves over five times the performance of Hopper FP8 (20,000 TFLOPS vs. 4,000 TFLOPS). The upcoming Rubin architecture will be even more powerful.
Another critical point is that “efficient models” do not mean “less AI computation overall.” As AI models become more efficient, the competitive focus of AI services expands from model building to reinforcement learning and inference technologies. Many reinforcement-learning techniques have been developed over time, but DeepSeek has highlighted the potential for even greater resource investment in RL. Notably, RL and inference technologies correspond to the second “AI Agent” cycle that NVIDIA has been advocating. It involves repeatedly running models, extending them to various applications, and using data to guide reinforcement learning. To realize this approach, lightweight models are essential: performance is achieved through pre-training, and distillation is used to convert them into a lighter model that won’t be crippled by inference computations. NVIDIA’s AI Blueprint tools streamline text-based interactions with sets of modeling options, boosting the usefulness of inference models for service providers.
AI semiconductors and AI datacenters remain a genuine moat for AI services. Making models lighter is simply a process to optimize computation costs and speed; it does not imply independence from the cost of AI semiconductors.
If DeepSeek V3 had used Blackwell for training, performance could have been improved at even lower cost (taking advantage of FP8 acceleration, faster training via NVLink, and improved memory bandwidth). Similarly, if the DeepSeek R1 model ran on Blackwell GPUs, it could save even more time and money. Reasoning demands more computing power. Hence, as the AI Agent era advances, AI semiconductor capability becomes more crucial. An AI datacenter’s scale signifies its capacity to support AI agents and AI services. Having the latest AI chips in sufficient quantity is a major competitive differentiator.
Ultimately, capital-intensive AI datacenters are still one of the strongest moats in AI services.
The HBM Memory Cycle Is Not Over
HBM is a high-priced memory semiconductor that emerged because current language models, whether for training or inference, require extremely high memory bandwidth. The continuing generational evolution of HBM in new GPUs, along with an increase in memory capacity, has long fueled expectations of robust HBM demand. Yet some argue that the high cost of AI model training is due to expensive GPUs and HBM, and that, as AI strives for greater efficiency, new technologies may enable a bypass of these costly components. If the upgrade cycle for GPU specifications slows, skepticism about HBM’s demand growth could intensify—warranting closer scrutiny. Are recent AI technology trends actually reducing the need for memory bandwidth?
MoE Structures and Quantization
MoE (Mixture of Experts) and quantization theoretically raise concerns that they might lower memory demand, but we believe the actual impact is minimal. An MoE strategy aims to increase efficiency by selecting and activating the most relevant “expert” for each input token, rather than activating all model parameters. DeepSeek V3 was trained with 671 billion parameters; at minimum, only 37 billion parameters are activated per token. Theoretically, that means only 6% of the memory bandwidth might be needed at any given moment.
However, while MoE can improve efficiency during training, it does not necessarily do so for inference. At inference time, you cannot predict which expert components will be needed, so prompts may cause all experts to activate simultaneously. Considering the data transfers between these expert modules, memory usage could actually increase. The growth in AI services centers on inference calculations, implying no real decline in potential memory demand overall.
Quantization in DeepSeek refers more specifically to low-bit training using FP8 or FP4 instead of training data in FP32 or FP16. Theoretically, moving from FP16 to FP8 would halve DRAM bandwidth needs. However, in practice, memory overhead during data computation can be significant. If the hardware does not natively support FP8 computations—as in NVIDIA’s Blackwell architecture—then FP8 data may still need to be cast back to FP16 during actual calculations, negating much of the memory savings. Also, extra data for optimizer states, scale factors, and zero points can cause further overhead. Since DeepSeek does not train everything exclusively in FP8, any FP8/FP16 casting during inference could end up increasing memory usage.
Could ASICs for Inference Significantly Reduce Memory Bandwidth?
It is true that inference ASICs are designed for efficient computation and thus incorporate various bandwidth-saving technologies. If operations are fixed and predictable, they can effectively reduce memory capacity. However, any ASIC capable of running LLMs at scale still requires HBM, simply due to the sheer number of parameters. Moreover, memory bandwidth could become an even greater bottleneck. For reinforcement learning (RL), which is a form of post-training but processes large volumes of data and requires fresh data repeatedly, HBM usage may increase even further. A large memory bandwidth is also necessary if you want to process multiple tokens simultaneously for faster speed and greater efficiency.
The fact that Google’s TPU and Amazon’s Tranium, currently the leading ASIC solutions, increase their HBM capacity with every product upgrade is definitive proof that demand for HBM is still robust—even in the ASIC space. Amazon decided to discontinue further development of Inferentia, which had smaller memory capacity, in favor of using Tranium chips for inference, starting in 2024.
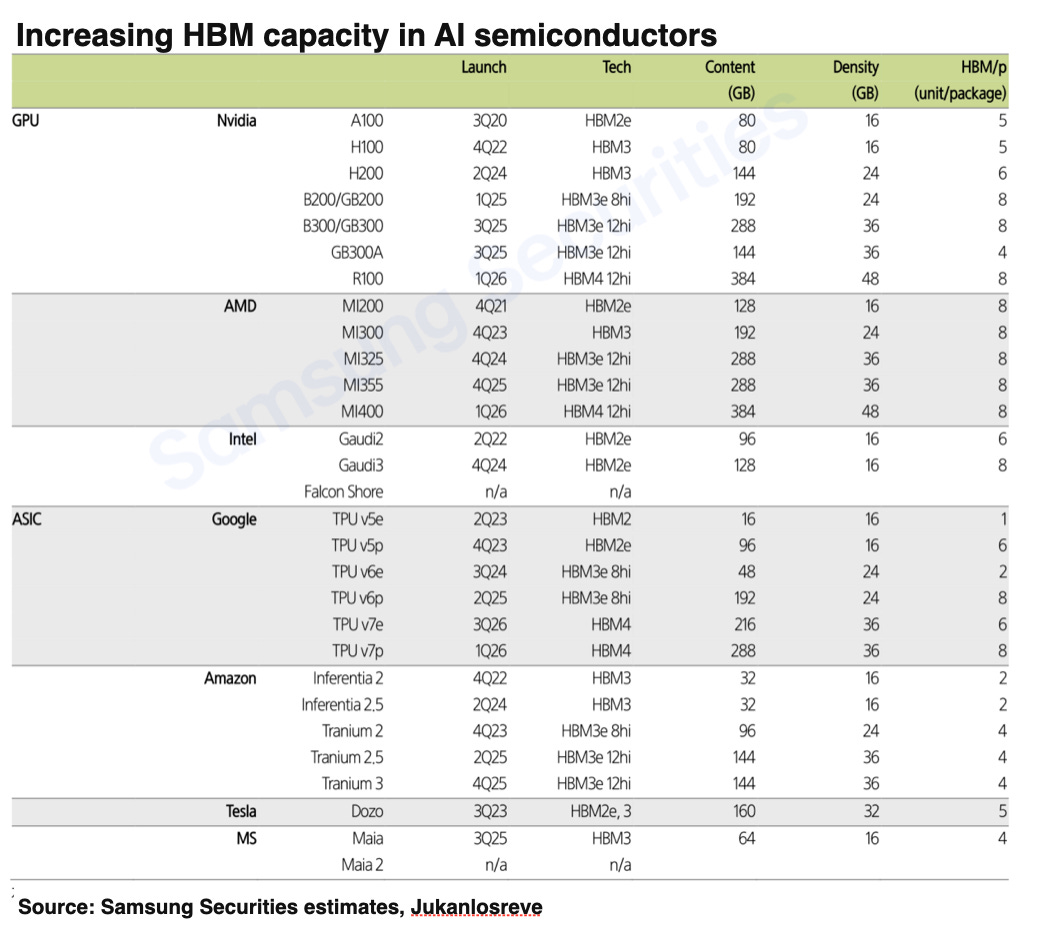
The Unwavering Power Efficiency of HBM Stimulates New Memory Demand
Why customers stick to expensive HBM
One of the main reasons customers are willing to pay a premium for HBM is its superior power efficiency, technically known as “performance per watt.” In terms of optimizing data transfer speeds and reducing power consumption per unit of capacity, HBM still has clear advantages. The principal challenge facing AI solutions today is power consumption: GPUs draw a lot of power, and the memory semiconductors supporting these GPUs also require significant power. Thus, we need to achieve greater power efficiency at the memory level. HBM in DRAM and high-capacity eSSD (or HAMR in the HDD space) in NAND are well-suited for this. Based on current technology, HBM is estimated to consume less power per unit capacity than standard DRAM. Moreover, in parallel data processing structures, increasing I/O (rather than merely raising the per-pin data rate) is considered more advantageous for AI systems.
Efficient AI models could spur additional memory demand
We believe that the proliferation of more efficient AI models and the expansion of AI services will drive new demand for memory. NVIDIA, for example, upgraded its inference board “Thor,” intended for robotics or autonomous driving, for release in 2025. If high-performance models can start running on lightweight devices with around 128GB capacity—thanks to techniques like distillation—this could spark demand in robotics, autonomous driving, and edge devices.
Naturally, as a heads-up, an eventual emergence of innovative, lower-cost (lower-power) high-performance semiconductors to replace today’s expensive CoWoS-plus-HBM architecture is inevitable. This is similar to how the field is evolving toward more efficient AI training and inference methods from a software perspective. But just as lightweight AI models have contributed to creating new market segments, ongoing innovation in AI semiconductors will likely expand overall semiconductor demand. We foresee the AI semiconductor market splitting into two segments: (1) high-spec, high-end products—AI accelerators paired with HBM—installed in AI datacenters, and (2) highly efficient solutions—a combination of SoCs and low-power AI memory—installed in devices and edge AI. The stock market might view this as a crisis at first, but will soon sense an acceleration in market growth.
Supply and demand outlook
As of now, we estimate that HBM demand will be around 24 billion gigabits in 2025. Considering the recent upward trend in AI Capex and the easing of CoWoS capacity bottlenecks, demand could stretch to as high as 26 billion gigabits. Meanwhile, supply remains constrained. The production mix is shifting towards higher-layer products, which are harder to achieve at stable yields, and HBM4—expected to debut in the second half of the year—will further reduce net die output. We thus believe that scaling up production will be more challenging than the market anticipates. Consequently, the likelihood of a supply-demand mismatch this year appears relatively low.
Spark for U.S.-China Rivalry
We believe the DeepSeck episode will ignite further competition between the U.S. and China, likely taking two forms:
1. Increased investment in the U.S. and
2. Heightened restrictions on AI exports to China.
Stimulus for AI Data Center Investment in the U.S.
As everyone knows, AI and semiconductors lie at the intersection of economics and politics. Political considerations can distort the purely economic figures. For example, in AI software (SW), the U.S. side emphasizes the need for vast capital and semiconductor dominance, whereas China stresses lower capital requirements and cost reduction. In AI semiconductors, U.S. narratives highlight low capital outlay, tight supply, and selective distribution, while China highlights bridging the technology gap and making heavy investments. This politicization makes it difficult for investors to objectively understand market realities and trends. Investors were particularly rattled by the DeepSeck shock because the U.S. side arguably inflated costs, while China minimized them—outcomes typical of political maneuvering, which often trigger both fear and justification for further investment.
In the U.S., this is likely to spur additional investment. The fact that Chinese firms managed to develop high-performance AI models despite mounting regulation—by employing various techniques and innovations—merely provokes greater American investment. Moreover, open-source models are now accessible to everyone. Ultimately, one must have a superior foundation model compared to rivals if the subsequent smaller, derivative models are to remain competitive.
It’s probably no coincidence that the Stargate Project was announced and Meta raised its CAPEX plans right around the time the DeepSeck model became public. In this process, higher-performance semiconductors may be a relative advantage for U.S. firms. Rather than focusing on DeepSeck’s success with a small number of inexpensive GPUs, one should consider how much more powerful a model they could have built with a larger number of latest-generation GPUs. In any scenario, regardless of how efficient future AI might become, the sheer scale of AI data centers can still confer a strong defensive moat.
Tighter Restrictions on China
However, there are associated risks. Now that DeepSeck has demonstrated China’s AI potential, it’s likely the U.S. will broaden the scope of its regulations on GPUs and HBM destined for China. Recent media coverage suggests that export controls on Chinese-produced chips like the H20 are foreseeable, and it appears Nvidia, aware of such risks, is not aggressively developing the H20.
We believe future restrictions on China will likely intensify. As algorithmic methodologies spread rapidly—especially among top-tier players (commoditization)—the supporting infrastructure becomes a critical point of differentiation in competitiveness. One key reason Nvidia’s share price has not rebounded quickly, even as misunderstandings around infrastructure spending have been dispelled, is persistent uncertainty caused by regulation.
Not only has the U.S. launched the Stargate project (USD 500 billion over 4 years), but China has also announced plans to invest CNY 1 trillion (USD 137 billion) over the next 5 years. It’s shaping up to be a full-scale, public-private national effort on both sides. Such large sums would not be discussed if algorithms truly rendered infrastructure unnecessary. Indeed, DeepSeck CEO Liang Yuan has cited U.S. GPU export controls as a key constraint. Although total control is impossible, each side will likely try to inflict maximum damage on the other in this AI power struggle.
The risk that China’s massive market could be walled off is indeed a negative factor for potential demand. However, it also underscores the strength of U.S. resolve regarding AI. Because AI will have a significant impact on future ecosystems, the U.S. government will likely continue to support the sector through policies like the CHIPS Act and the Stargate project, while private companies also keep raising their capital expenditures. As a result, we cannot rule out a scenario in which AI semiconductor demand—and by extension AI memory like HBM—once again sees upside potential similar to last year.
Investment Strategy: Searching for New Opportunities After the Correction
A market pullback is inevitable but likely to be short-lived.
Recent stock market volatility is not solely due to the technical shock brought on by DeepSeek. We believe a combination of factors—investors crowding into certain sectors, uncertainties around the U.S.-China AI rivalry, and macroeconomic concerns unrelated to AI—has led to the current situation. Given the time lag between the actual event and market reaction, the DeepSeek incident may just have been a simple trigger. In other words, regardless of what DeepSeek truly represents, the market imbalance and fear it sparked will need time to subside. Over the near term, we anticipate continued high volatility or a correction phase in the stock market.
The Correction Will Be Brief
We do not believe this correction phase will be prolonged, chiefly because interest in AI remains strong. We do not see signs of investor funds shifting from AI into other sectors. Meanwhile, cloud providers are still in an expansionary investment cycle, and upcoming earnings releases are expected to show that the overall landscape remains unchanged. Most importantly, many investors have likely already hedged their risks during the recent steep market declines.
What to Buy?
1. Semiconductors, Cloud, and Software: We anticipate a recovery—or further gains—in these sectors. We believe DeepSeek’s emergence has spotlighted one facet of AI-driven growth, but investors have misread it as a risk, thus creating opportunities.
2. Korean Tech Stocks: During this correction, we expect Korean tech names—which have been less subject to speculative inflows—to outperform over the near term.
3. Korean Internet, On-Device AI, and Device Makers: We see potential upside in sectors that were previously considered peripheral to AI. On the other hand, as interest in pre-training scale-ups wanes, focus may shift away from the surrounding infrastructure of data centers.
Potential Catalysts
The key catalysts are cloud capex trends and Nvidia’s earnings results, as they are the strongest indicators that the overarching AI narrative remains robust. Achievements in AI model “lightweighting” in the U.S. could also serve as a significant rebound trigger. Falling API prices and the emergence of AI Agent services are, in fact, positive developments in the natural evolution of AI. As high pricing was a barrier for many AI-related businesses, the market will welcome any new entrants and capital infusions from competitors who were previously hesitant due to cost constraints.
What Is the Real Risk?
A definitive signal of peak AI demand would appear if we witness a decline in cloud spending. In this light, DeepSeek’s news more likely underscores additional cloud demand rather than dampens it. We suspect a genuine peak-out would occur once AI services that “work” diverge from those that do not, in the early stages of commercial deployment. At present, the market treats virtually all potential AI services—regardless of feasibility—as part of the cloud’s future token demand.
Solid Nvidia and Top ASIC Player Broadcom
We remain positive on the AI semiconductor space. Intense competition in technology R&D means that companies will continue trying to secure as many best-in-class chips as possible—a trend we expect to persist this year. Ongoing capex expansion by the Big Tech players in 2025 reaffirms this view.
We continue to believe Nvidia will be the market leader in the near term. Even so, companies will seek to differentiate themselves amid growing competition. ASIC development is one such avenue—particularly relevant as inference demand surges—so we remain optimistic about that as well. Broadcom, rumored to be involved in three active projects and said to have secured customers like OpenAI and Apple for new AI ASICs, is another name worth watching.
While it may appear that GPUs and ASICs compete, we think both can grow in tandem amid an expanding AI infrastructure. However, in a fiercely competitive industry, growth rewards typically accrue disproportionately to market leaders. This is why we remain positive on GPU leader Nvidia and ASIC leader Broadcom.
Misconceptions About Memory Will Soon Be Resolved
Skepticism toward general-purpose semiconductors and rising doubts about AI may negatively impact near-term memory semiconductor and supply chain considerations. However, we believe these concerns could lead to a rebound inflection point. The fact that new product roadmaps show increasing HBM capacity is powerful evidence that memory bandwidth remains essential in the AI ecosystem. Each time AI costs are reduced, the market will pivot to the possibility of further expansion in the AI ecosystem. The potential for AI to spread to edge devices could reinvigorate general-purpose demand, which has been relatively subdued.
In particular, we anticipate that Korean memory manufacturers—less prone to speculative bubbles—may outperform during any upcoming market correction.
Cloud Is Still Strong
The emergence of DeepSeck is not necessarily bad news for cloud providers; in fact, we see it as positive. That’s because both training and inference are likely to drive increased demand for cloud services. As mentioned in DeepSeck’s own paper, building a distilled model requires a “good foundation model.” This explains why the distilled version of R1 performs better than the distilled version of R1 Zero. The need for computational resources to create next-generation models—and to refine and distill them—will persist. Likewise, the emergence of open models focused on cost-effectiveness naturally leads to the growth of AI services, i.e., inference.
Although there may be ongoing challenges concerning ROI, cloud companies have little reason to hold back on capex. Microsoft, which just announced its earnings, maintained its aggressive capital spending stance. CEO Satya Nadella’s remark that “as AI becomes more efficient and accessible, demand grows exponentially” captures the current situation well. Overall, these industry developments reinforce a positive outlook for Big Tech’s cloud business.
What About OpenAI?
OpenAI may feel uneasy about DeepSeck’s progress, as the latter drew heavily on OpenAI’s models and research direction. However, the disruptive impact of DeepSeck is likely aimed more at the open-source and mid-market segment, rather than undermining the frontier-model segment. In fact, there may be more reason to focus on Anthropic—whose approach centers on monetization via API—or Meta, which is reportedly operating war rooms in response to competition.
Although DeepSeck’s app did briefly surpass ChatGPT on the App Store, this may prove short-lived. Further data on user activity, retention, and time spent will be necessary to confirm its staying power. Following a surge of interest, DeepSeck experienced service disruptions and eventually restricted sign-ups to those with Chinese local phone numbers. Even offering inference services requires substantial computing power, and hidden semiconductor resources are presumably limited.
Even putting aside concerns about bias, safety, and privacy—known weaknesses of DeepSeck’s model—OpenAI’s scale in data, computational resources, and ecosystem should keep it competitive. OpenAI’s latest Model 03 already surpasses Model 01 in numerous respects, and as Sam Altman has noted, competition can serve as motivation. From a user’s perspective, it would be welcome news if this rivalry compels OpenAI to release a more powerful, lower-cost next-generation model sooner.
An Opportunity for Software Companies
In contrast to the recent dip in AI infrastructure stocks, shares of many AI software companies have fared relatively well. Improved algorithmic efficiency in the model layer and lower costs are ultimately beneficial for enterprise software looking to deploy AI. Notably, the success of R1’s distilled model showcases the possibility of building smaller, domain-specific models with high performance—potentially broadening end-user applications and use cases.
We predict 2025 will be the year when AI services truly go mainstream, driven in part by more capable inference models, but also by dramatically falling API prices. Fierce competition in the foundation model layer poses no real downside for the application layer. However, it is important to remember that these advancements—pursuing lightweight, efficient models—did not emerge overnight. For software providers delivering end solutions, the key question is whether they can fully seize the opportunity of the “Agentic AI” era. Middleware vendors, for their part, must determine how effectively they can cater to rising inference demand with specialized solutions and thereby reap tangible benefits.
A Second Chance for “Korean AI”
The decline in AI costs and the growth of open-source models could offer a second opportunity for Korean internet firms. Since initiatives like Naver’s HyperClova and Kakao’s KANA were partially developed by training on open-source models, the availability of more affordable open-source models could further enhance their performance. Naver’s plan to integrate generative language models into its search, shopping, advertising, and content could boost its service competitiveness. Kakao, meanwhile, aims to strengthen its chat services with a conversational AI chatbot. Both strategies stand to benefit from these developments.