Samsung Securities: Cloud Bottlenecks and Misconceptions about DeepSeek
The market is mistaken

TLDR:
• The capacity constraints of hyperscalers have led to an increase in Q following a drop in P that Capex failed to match. Given the forecast of aggressive Capex investments by Big Tech in the future, any doubts about the overall direction are unwarranted.
• In infrastructure investments, high-performance semiconductors are always prioritized. With the resolution of bottlenecks, a recovery in stock prices is anticipated.
WHAT’S THE STORY?
AI Capacity Bottlenecks Take Center Stage:
The key issue in Big Tech’s Q4 performance is the slowdown in growth of the cloud segment among hyperscalers. This is due to infrastructure shortages driven by an explosive surge in AI demand and the effects of exchange rates. Factors such as securing data center sites, adopting in-house semiconductors, and power supply challenges have collectively caused cloud revenue growth to fall short of expectations. In response, major tech companies including Microsoft, Alphabet, Amazon, and Meta have announced large-scale Capex investments. We expect a substantial easing of capacity constraints to emerge in the second half of 2025. With AI revenue growth remaining robust and an increasing share of inference spending alongside ongoing improvements in operating margins, any doubts about the trend are unnecessary.
High-Spec Takes Priority in Infrastructure Investments:
The emergence of lightweight inference models has raised concerns over a slowdown in the adoption rates of AI accelerators and HBM. However, semiconductors for infrastructure differ from those used in consumer applications. High-performance products are prioritized not only for their superior performance but also for their cost-effectiveness, as they are designed to reduce the total cost of ownership (TCO) for clients. Even for lightweight inference models, Blackwell products hold an advantage. Although ASIC adoption is on an upward trend, as noted by AMD CEO Lisa Su, it will not exceed certain limits—largely due to the inherent constraints of ASIC solutions in rapidly evolving AI workloads. In particular, the trend from 2025 onward of ASICs increasing their HBM capacity to levels comparable to GPUs proves that memory bandwidth remains a critical specification even for inference models.
Semiconductor Adjustment Phase and Conditions for Resolution:
Some investors are concerned that the NVIDIA myth is being shaken. However, this adjustment phase is no different from previous ones experienced by NVIDIA. The current phase hinges on resolving the bottlenecks in both demand (cloud) and supply (Blackwell), with recovery expected as concerns about Blackwell subside and cloud growth rebounds. In this cycle, NVIDIA’s adjustment phase has lasted anywhere from one month to five months. Nevertheless, if the AI theme continues to hold strong in the stock market during this period, NVIDIA’s benefits could become prominent at any time.
On-Device AI Model Propagation:
Owing to the success of DeepSeek and the competitive development of lightweight models, it is anticipated that AI investments will resume—especially in the Chinese device market. Increases in high-spec application processors (APs) and memory capacity are expected. On-device AI will primarily grow alongside the expansion of services such as camera interpretation (e.g., Gemini Live) and local data search (e.g., MS Recall).
AI Capacity Bottlenecks, Misunderstood Hyperscalers
The biggest topic in Big Tech’s Q4 performance is the underperformance of hyperscalers’ cloud segments. The reasons can be broadly summarized into two points:
1. A shortage of AI capacity, and
2. The impact of exchange rates (resulting in a 1–2 percentage point effect).
In addition, Microsoft experienced a deepening decline in growth within its non-AI segments due to changes in its indirect sales strategy.
Ultimately, the critical issue is the shortage of AI capacity—the very issue that had been holding back Microsoft’s stock since the latter half of last year. In Q4, as Alphabet encountered this issue, even Amazon—renowned as a master of infrastructure investment and management—faced the same challenge, further heightening investor concerns.
Ironically, this problem stems from the explosive surge in AI demand. With the recent emergence of high-performance, compact inference models, prices (P) have plummeted sharply while service development demand (O) has surged. Under normal circumstances, revenue growth should occur as the increase in quantity (Q) more than offsets the decline in P. However, due to the capacity shortage, Q cannot be adequately absorbed, and revenue growth is falling short of expectations.
The causes behind these capacity constraints are multifaceted. Key factors include difficulties in securing data center sites, the timing of large-scale adoption of new in-house semiconductors and the ensuing supply chain delays, as well as power shortages. Additionally, various other variables—such as the AI adoption cycles of enterprise customers and the timing of technological advancements—must be taken into account.
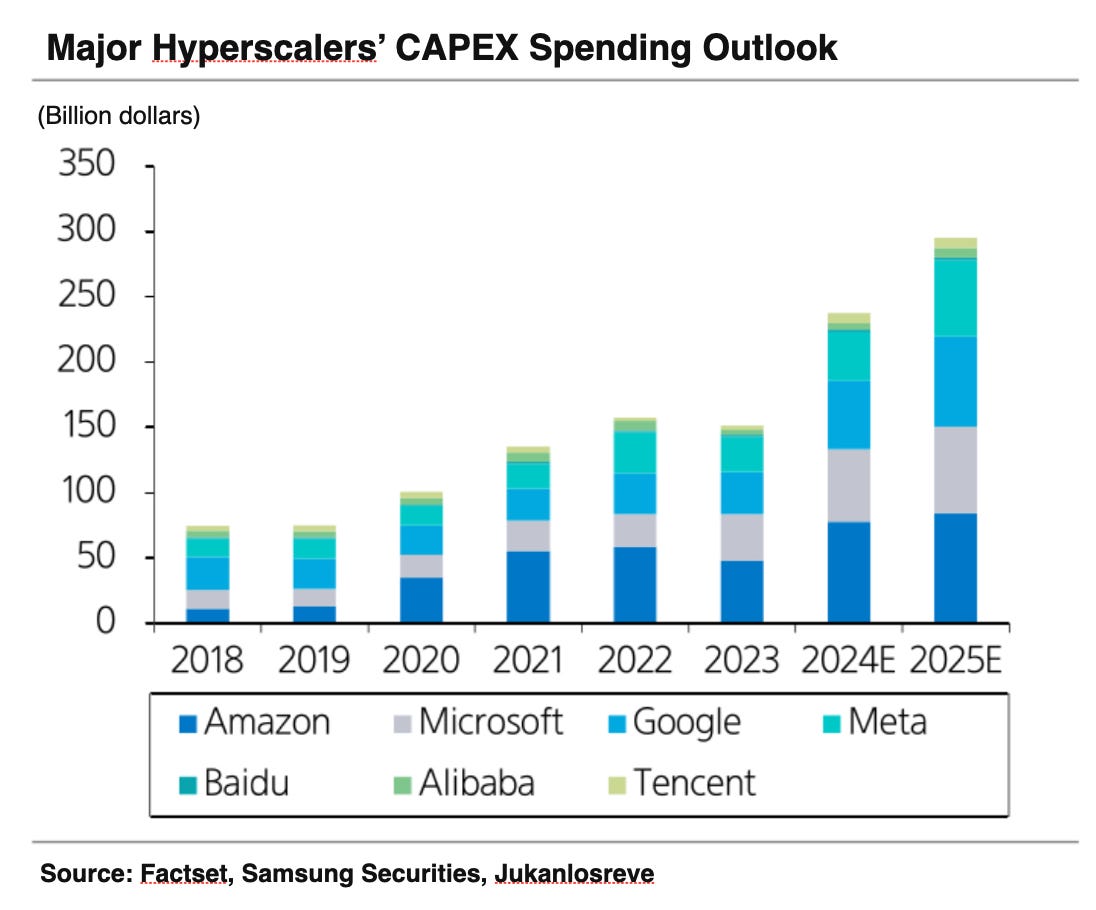
In fact, large-scale CapEx investments aimed at resolving this issue are a common theme in the recent Big Tech results. While the market expresses concerns about ROIC, the real problem appears to be an overall lack of sufficient investment.
• Microsoft: FY25 (ending June 2025) CapEx is projected at $87.8 billion (with F3Q and F4Q expected to be similar to F2Q’s $22.6 billion) versus FY24 (ending June 2024) at $55.7 billion, marking an increase of +57.6%.
• Alphabet: FY25 CapEx guidance is $75 billion versus a consensus of $58.8 billion and FY24 at $52.5 billion, an increase of +42.9%.
• Amazon: FY25 CapEx guidance is $105 billion versus FY24 at $78.2 billion, representing a +34.5% increase.
• Meta Platforms: FY25 CapEx guidance is between $60–65 billion versus a consensus of $52.6 billion and FY24 at $37.3 billion, an increase of +67.8%.
The full-scale resolution of these capacity constraints is expected to occur in the second half. Until then, growth will continue, though its trajectory remains uncertain. In 2025, while the synchronization between new capacity deployment and cloud revenue is anticipated to improve, outcomes could swing either way—yielding a surprise, as was the case with Alphabet in Q3, or resulting in disappointing performance like in Q4. This inherent uncertainty is a factor that could weigh on short-term stock performance.
The decline in P is believed to have been driven more by training than by inference . Ultimately, if aggressive CapEx investments succeed in increasing capacity on schedule, the benefits from inference growth—which typically commands higher margins compared to training—are likely to persist. In fact, an increased share of expenditure on inference is already being observed.
Moreover, given that the launch of inference models into full-scale service is relatively recent (with OpenAI 1 and 03 having commenced services on September 13, 2024, and February 1, 2025 respectively, and Google Gemini 2.0 on December 11, 2024), the potential for continued profitability improvements remains strong. It is also encouraging to note that the operating margins of the three major hyperscalers continue to improve; if they are generating strong profits, there is no reason to cut back on investments.
In essence, this is merely a timing issue—the trajectory of AI revenue growth for hyperscalers remains intact. Microsoft’s annual AI business revenue has reached $13 billion, comfortably surpassing the $10 billion level mentioned last quarter. The robust trend in AI infrastructure investment is also likely to continue. In the same vein, stocks of related companies (such as NVIDIA, Broadcom, Marvell Technology, etc.), which had faced corrections following the DeepSeek incident, are rebounding as they digest the Big Tech results.
Using High-Performance Semiconductors in Infrastructure Investments Is the Obvious Choice
Are the Proliferation of Inference Models and Cloud Providers’ Infrastructure Optimization a Crisis?
The spread of inference models and the drive for infrastructure optimization by cloud providers send a message to semiconductor companies—a sense of crisis that high-end demand growth may no longer materialize. In first-generation LLMs that dramatically increased parameter counts and in second-generation LLMs where overtraining data yielded results, there was no emphasis on optimizing for GPU parallelism or HBM bandwidth—it was simply a case of “the more, the better.” However, in third-generation LLMs, which require multiple runs to boost test time performance, optimizing the efficiency of individual semiconductors may become even more critical than raw parallel processing speed. Additionally, the trend of decreasing GPU usage and increasing ASIC adoption in the infrastructure optimization process by cloud providers could be interpreted as a reduction in the share of high-end components.
High-Performance Accelerators and HBM Remain Top Investment Priorities:
1. Infrastructure over Consumer Needs:
AI accelerators and HBM are deployed for infrastructure rather than consumer applications. In this realm, reducing the customer’s total cost of ownership (TCO) is far more important than the peak performance of an individual product. Regardless of AI model trends, new GPU products inherently help lower client costs compared to their predecessors.
2. Advantages Evident in Lightweight Inference Models:
The benefits of Blackwell are apparent even in lightweight inference models such as DeepSeek-R1 and Gemini 2.0 Flash-Lite. The increased transistor density achieved through multi-die technology not only boosts efficiency but also aids in quantization computations (e.g., FP4, FP6) and is reflected in extensive data usage improvements via features like Transformer Engine 2nd Generation and NVLink upgrades.
3. ASICs in a Changing AI Landscape:
Since ASICs are semiconductors optimized for specific workloads, in an environment where AI model trends are shifting rapidly, leveraging GPGPUs alongside adaptable software architectures may prove more beneficial for data center optimization.
4. Memory Bandwidth Remains Critical:
The projected increase in ASICs’ HBM capacity to GPU levels (144GB, 192GB, etc.) starting in 2025 indicates that memory bandwidth will continue to be a crucial factor, even for inference models.
Resolving Bottlenecks Will Settle the Adjustment Phase:
One concern is that the long-held belief—that GPUs and HBM alone can solve all AI challenges—is now being questioned. The notion that high-density integration of GPUs and HBM suffices for both AI training and inference was never disputed; yet the emergence of analyses reexamining semiconductor strategies signals a shift. Moreover, while proxy players for AI growth were once limited to companies like NVIDIA, SK Hynix, and their supply chains, a broader range of alternatives is now emerging from the application side. Nonetheless, this situation is expected to mirror the adjustment phase NVIDIA experienced over the past two years. Addressing the bottlenecks in both demand (cloud) and supply (Blackwell) is crucial—and recovery is anticipated to come through:
1. An adjustment period of roughly three months,
2. The alleviation of concerns regarding Blackwell, and
3. A rebound in cloud growth rates.
The key takeaway is that the AI theme remains robust.
Spreading AI Models On-Device:
The success of DeepSeek and the competitive development of lightweight models are expected to rekindle AI investments, particularly in the Chinese device market. Unlike Samsung and Apple—which have prominently showcased AI—Chinese companies had seen a decline in AI focus. However, on-device AI is poised to become a powerful rallying cry, keeping pace with a rapid, transformative expansion. This shift is anticipated to drive an increase in high-performance application processors and memory capacity. On-device AI will likely propel the growth of services such as camera analytics (e.g., Gemini Live) and local data search (e.g., MS Recall).