
OpenAI’s Strategy and the Implications of GPT-4.5
GPT-4.5 failed, but it is meaningful.

Before we begin, please note that this post is an English translation of a report by Mirae Asset Securities Korea.
A few days ago, OpenAI published a blog post outlining its latest position on AI safety and alignment. In truth, the content was so predictable it almost felt as if it were written by AI. This piece extends the charter they have long emphasized—that “AGI should benefit all of humanity”—and reiterates the need for careful monitoring and a phased approach, in light of concerns that, in the later stages of AGI development, the process could devolve into a reckless “competitive race” without sufficient safety measures.
What stands out in this blog is the projection that AGI has the potential to solve nearly all of humanity’s problems and will have a transformative impact “within a few years.” It also stresses that remaining at the cutting edge of AI capabilities is necessary to effectively address the social impact that AI will create. Furthermore, OpenAI expresses its conviction that AGI, as a tool capable of solving almost all of humanity’s problems, will bring about positive change—though it is clear that they intend to lead that change themselves.
The blog explains that AGI is not the result of a sudden leap but rather the outcome of a continuous process of incremental development. From this perspective, OpenAI is adopting a strategy of iterative deployments of current models rather than waiting for one pivotal moment. This approach, which implicitly acknowledges that there is no perfect solution, can be seen as a cautious stance—a step back from the earlier overconfidence.
What is OpenAI’s True Intention?
It is important to analyze OpenAI’s actual intentions beyond the surface message. While the blog contains a theoretical discussion on AI safety and governance, it is underpinned by several strategic calculations. Firstly, by re-establishing its image as a “responsible AGI developer,” OpenAI aims to reassure stakeholders that its recent rapid actions are being conducted within controlled bounds.
The strategy of gradually deploying powerful AI may outwardly appear to be a safe and cautious introduction of AGI; however, in reality, it is also an effective way for OpenAI to capture the market. Thanks to its preemptive releases, OpenAI has effectively established its standard, gaining a significant advantage over competitors through massive user data and widespread brand recognition. ChatGPT, for example, is on track to surpass 400 million weekly active users by early 2025, exhibiting explosive growth by adding 100 million net users in roughly six months.
Recently, OpenAI has continued to expand AI features across both its PLUS tier (priced at $20 per month) and its free tier, a strategy interpreted as an effort to fend off open-source challengers while retaining its user base. Moreover, there are reports that rather than raising the $20 monthly subscription fee for “ChatGPT PLUS,” OpenAI is considering lowering it—a direct response to the emergence of lower-cost models from Chinese companies like DeepSeek.
Over the next few years, OpenAI is prepared to incur billions of dollars in operating losses (with a $5 billion loss projected for 2024 alone and a cumulative $44 billion loss by 2028) as it continues aggressive investments. In this context, to ensure continuous funding, OpenAI will need to provide clear performance guarantees to investors. Thus, despite the cautious tone of the blog, competitive pressures in the industry will likely compel OpenAI to accelerate its AGI development timeline and boost its technological investments.
Furthermore, with the emergence of formidable competitors such as xAI, Anthropic, and DeepSeek, OpenAI is fighting to maintain its technological edge. As other leading companies rapidly develop large language models, OpenAI has been responding by consecutively releasing new models like GPT-4.5. This move is also part of a strategy to reassure investors. There have even been reports about the potential launch of a high-priced agent subscription model (ranging from $2,000 to $20,000 per month).
The news of such premium AGI services serves to imprint OpenAI’s technological superiority in the market and demonstrates the monetization potential to investors. In other words, by showing that there is real demand for AGI, OpenAI is taking steps to reassure investors. This aligns with earlier remarks by CEO Sam Altman in his personal blog earlier this year, where he stated, “We now know enough about how to build AGI,” and predicted that “AI agents will soon be deployed in real-world operations.”
In essence, the pricing strategy—reaching several thousand dollars per month—is aimed at positioning AGI in a high-end premium segment that is difficult to imitate, thereby emphasizing qualitative advantages over competitors. By packaging and announcing its strategy as a gradual deployment according to the original plan, OpenAI seeks to convey that its progress is a legitimate technological advancement rather than a hasty reaction to intensified competition. OpenAI is intent on cultivating an image of “cautious yet ahead of the curve” to maintain stakeholder trust amid rapidly changing competitive dynamics.
In summary, in the current AGI race, OpenAI is pursuing a three-pronged strategy: (1) locking in as many users as possible to its platform to capture the industry standard, (2) creating a premium market through top-tier AGI capabilities, and (3) outwardly presenting itself as a responsible pace-setter.
2. The 600 Million Won-per-Year Agent Considered by OpenAI
(1) Can the Agent Generate Triple the Revenue?
According to internal documents revealed a few weeks ago, the contract between OpenAI and Microsoft sets a financial target: AGI is considered achieved when OpenAI accumulates a profit of $100 billion. In other words, achieving enormous profits becomes the benchmark for AGI success. This suggests that while OpenAI’s stated value of benefiting humanity is important, it also aligns with a practical, investor-oriented goal.
Furthermore, a few days ago, a report from The Information revealed that part of OpenAI’s plan to achieve what they define as AGI was leaked, sparking considerable attention. It emerged from discussions with investors that some OpenAI executives are planning to charge $20,000 per month for the use of a high-end AI agent, intended for PhD-level “high-caliber research work.” This fee is comparable to the pre-tax annual salary of 610 million KRW earned by some employees.
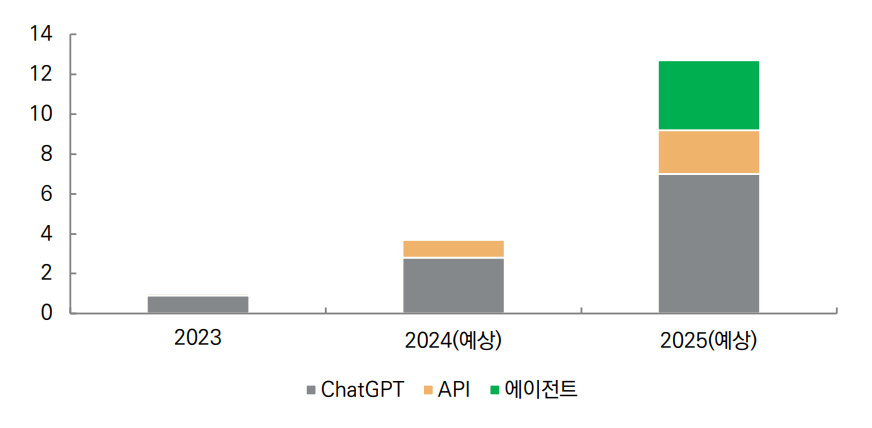
The report also includes OpenAI’s revenue data: $1 billion in 2023, with an expected $3.7 billion in 2024. In this Figure, the gray portion represents ChatGPT revenue, while the light orange section represents API revenue from developers. The revenue forecast for 2025 is projected to reach $12.7 billion, and notably, a new green bar appears—representing revenue from high-priced agents. This green segment appears to be as large as the total revenue for 2024. It seems that the newly added agent segment for 2025 is related to OpenAI’s plan to charge $20,000 per month for PhD-level agents. It is particularly interesting that this segment is estimated to account for roughly one-third of OpenAI’s overall revenue growth this year.
Furthermore, The Information’s report stated that by 2026, total revenue is expected to reach between $26 billion and $28 billion. It is worth noting that OpenAI has been in discussions since earlier this year about an additional funding round of $40 billion; if successful, the company’s valuation could rise to $340 billion. Based on the midpoint of the 2026 revenue forecast, the EV/Sales valuation would be about 12.5x—comparable to levels seen during the dot-com bubble.
The newly revealed subscription model plan by OpenAI is broken down as follows:
• Entry-Level Agents: $2,000 per month, targeted at high-income knowledge workers who can be replaced by remote workers.
• Mid-Level Agents: $10,000 per month, intended for mid-tier software development (OpenAI has internally stated that it possesses a model that is ranked around 50th globally according to Codeforces).
• High-End Agents: $20,000 per month, for research agents at a PhD level.
OpenAI expects that these agent products—essentially employee-replacing agent solutions—will account for approximately 20–30% of the company’s revenue.
(2) The Emergence of High-End Agents and Open Source
At this point, the greatest concern is the extent of labor market disruption due to workforce replacement and automation. The key issue is how many workers will be replaced—whether it will be as low as 5% or as high as 50%—since the outcome would be dramatically different. If it reaches as high as 50%, it could lead to a dreadful scenario akin to Thanos snapping his fingers.
Another important indicator is how cost-effective AI agents are compared to human workers. If the cost of an agent is only, say, 5% cheaper than the cost of hiring and retaining a human employee, the pace of change might be quite slow. As OpenAI officially asserts, there may be a buffer period—“time to adapt, time to develop solutions for those replaced by AI.” However, one must consider the critical variable that OpenAI is under intense competitive pressure. If AI agents prove to be more than 50% cheaper, the incentive for companies to adopt them will increase dramatically.
What would happen if the cost of an agent were only half that of a human? Moreover, agents can operate 24/7, and with continuous updates, their capabilities will keep improving. Just as Tesla’s autonomous driving performance continues to improve through OTA updates (with Tesla’s driving intelligence now advanced enough to operate smoothly in China), AI agents will similarly continue to enhance their performance.
In such a scenario, if a company like DeepSeek were to release agents that are several dozen times cheaper than those offered by OpenAI, what hiring strategy might companies adopt? If a product emerges that exhibits 80–90% of human-level intelligence but is ten times cheaper, public support for open source could shift dramatically. If agents with equivalent capabilities are released as open source, making them accessible at a low cost, the resulting uncontrolled change could have a “highly disruptive” impact.
Paradoxically, while OpenAI is planning its own agents, it also seems to be anticipating some degree of backlash. Thus, through its blog posts on AI safety and alignment, OpenAI emphasizes “preemptive AI safety” and seeks to preempt stronger government regulations while cultivating an image as a “benevolent company.” Sam Altman’s testimony before the U.S. Congress in 2023 and his world tour meeting global leaders can be interpreted as efforts to shape regulation in a way that benefits OpenAI’s interests.
By securing its position as a collaborative advisor on AI policy, OpenAI is positioning itself to advocate for a regulatory framework that could serve as a significant barrier to competitors who are less capable or resource-constrained. It remains difficult to determine whether OpenAI’s strategy of warning about the threat of AGI while promising the development of “controlled AGI” constitutes “gaslighting” or a genuine appeal; the truth likely lies somewhere in between.
3. The End of an Era… GPT‑4.5
(1) A Colossal Model That Consumed 10× the Computing Power
On February 27, OpenAI released GPT‑4.5. Unlike previous models, however, there was neither raucous promotion nor any significant hype. Notably, for the first time, key researchers did not appear in the promotional videos. This may suggest that OpenAI has internally prioritized other projects (for example, inference models) or that their internal evaluation of GPT‑4.5 was not very positive. Furthermore, until just a few days ago, this model was available only as a research preview to Pro subscribers paying $200 per month, making it relatively unknown to the general public.
GPT‑4.5 is, in one respect, a monumental model—simply because it is vastly larger than GPT‑4’s staggering 1.8 trillion parameters. Some analyses speculate that GPT‑4.5’s model size may exceed 5 to 10 trillion parameters. According to Andrej Karpathy, one of OpenAI’s 11 founding members, even a “0.5” version bump implies a tenfold increase in computing power. In other words, an enormous amount of computing resources has been invested in developing this model.

The model’s size means it has been trained on a far greater number of tokens, and consequently, the volume of data it “remembers” (albeit in a complex and somewhat blurred manner through its embedding vectors) is greater than that of any other model. As Anthropic CEO Dario Amodei has remarked, “Language isn’t made up solely of simple patterns; complex and rare patterns form a long-tail distribution, and as a network gets larger, it can capture more of these patterns.” In short, the great advantage of GPT‑4.5’s massive size is its ability to handle even higher levels of abstract concepts more effectively.
Quantitatively, GPT‑4.5 has achieved modest improvements over GPT‑4. Although the law of diminishing returns does apply, the scaling law of pre-training appears to remain valid—at least for now.

Of course, the leap from GPT‑3.5 to GPT‑4 and from GPT‑4 to GPT‑4.5 are not equivalent. Contrary to public expectations, the upgrade to GPT‑4.5 did not deliver a revolutionary performance boost compared to OpenAI’s previous models. In fact, many observers noted that it marked the first instance when the “lead” in OpenAI’s raw LLM intelligence seemed to falter. While DeepSeek’s R1 shocked on a cost basis and Anthropic’s latest model along with xAI’s Grok 3 showcased astonishing human-like qualities, GPT‑4.5 left many people disappointed.
Within the AI development community, there is a strong criticism that GPT‑4.5 is “merely bigger” and lacks new functionality. It receives high marks for natural language processing, creativity, and image comprehension, but it falls short in coding abilities and software engineering tasks. For developers—particularly those for whom coding skills are paramount—the model is hardly appealing. In areas that require reasoning, such as advanced mathematical problems and complex coding tasks, its performance is significantly inferior compared to smaller models like o3‑mini (high).
Moreover, the anticipated reduction in hallucinations did not see a marked improvement. As Sam Altman and Dario Amodei had predicted, it was expected that increasing model size would dramatically reduce hallucinations. Yet, while GPT‑4o recorded a hallucination score of 0.52 and o1 brought that down to 0.2, GPT‑4.5 essentially remains at the same level as o1 with a score of 0.19. It is better than GPT‑4o, but the key point is that it still produces as many nonsensical outputs as its much smaller, less experienced “younger cousin.”

Due to its enormous size, GPT‑4.5 also comes with a host of limitations. It is likely the slowest model available on the market. In actual use, one might feel as though they have been transported back to the early days when GPT‑4 first launched two years ago. Initially, even Pro users were subject to a weekly message cap for GPT‑4.5. Although rollout to Plus subscribers began a few days ago, there remains a limit of 50 uses per week.
This is because GPT‑4.5 costs 30 times as much per input and 15 times as much per output compared to GPT‑4o. For reference, the competing model Anthropic’s Claude 3.7 Sonnet is priced similarly to GPT‑4o—approximately $3 per million input tokens and $15 per million output tokens. Consequently, the exorbitant API pricing is a common grievance among developers. GPT‑4.5 is, without exception, the most expensive model, making practical applications nearly unfeasible. While the full inference model (as opposed to the mini version) is priced at $15, this model costs $75. Furthermore, in the Cursor IDE environment it is reported that each request costs about $2, which only adds to the growing discontent among developers over the price burden.
(2) GPT‑4.5 Has Higher EQ Than IQ
Interestingly, when Andrej Karpathy conducted a direct preference poll comparing the outputs of GPT‑4.5 and GPT‑4, far more people preferred GPT‑4.5’s responses. Karpathy noted, “Even when GPT‑4 improved over GPT‑3.5, the performance gains were subtle.” In fact, while Korean users found GPT‑4’s multilingual capabilities outstanding, it took very specific questions in English-speaking contexts to discern differences between GPT‑3.5 and GPT‑4. He reiterated that such ambiguous improvements are difficult to articulate and even harder to comprehend. It is challenging to market subtle enhancements.
Our team decided to test Karpathy’s view by presenting GPT‑4.5 with an absurdly unique prompt. As detailed in the [Appendix], GPT‑4.5 managed to capture the brief context provided by our team and transform it into entirely creative phrasing—a response that was impossible with GPT‑4, with only xAI’s Grok 3 coming close in creative output. Although GPT‑4.5 appears superior in many ways, it is hard to quantify or pinpoint exactly how; hence, we have provided examples in the [Appendix]. (We encourage readers to have an in-depth conversation with GPT‑4.5.)
Nonetheless, I found that the advanced intelligence of GPT‑4.5 is unmistakable in practice—as I increasingly found myself naturally favoring it over Claude or Gemini. The more I used it, the more it established itself not merely as a content generation tool, but as an intellectual partner offering social and philosophical insights. I believe this is what truly matters to users. Even if the improvements are ambiguous, the “emotional intelligence” that makes one want to keep conversing with the AI is key. In fact, OpenAI repeatedly emphasized in GPT‑4.5’s system card that the improvements are in EQ rather than IQ. Our team, like Andrej Karpathy, believes that the real battleground for AI advancement will not be in logical or mathematical prowess (the quantitative aspect), but in areas such as emotional empathy with humans, creative expression, and subtle qualitative differentiation.
Of course, using GPT‑4.5 also reveals the inherent limitations of AI. While AI can scale up the volume of information, it lacks the ability to simplify complexity through genuine insight and judgment. It does not have the individual personality that each human possesses. In reality, it is difficult to expect an AI—tasked with handling countless clients collectively—to exhibit such distinctive personality. Each human, through decades of life, develops a bias that enables them to intuitively discern what is important and meaningful from raw information, distinguishing between “noise” and the correct “signal.” However, although AI may have a wealth of “indirect experience” data, it lacks the parameters associated with a personal bias imbued with its own personality.
Thus, fundamental cognitive abilities such as strategic insight, intuition, and judgment will likely become even more valuable in the AI era. Moreover, AI shows weaknesses in convergent innovation—creatively connecting insights from seemingly unrelated domains to create something new. The ability to traverse diverse contexts and spontaneously link insights will provide humans with a unique competitive advantage in the AI era. We have now entered an era where the ability to actively discover insights between pieces of knowledge is far more important than merely possessing that knowledge, and this will be the key to surviving in the age of agents.
(3) GPT‑4.5 Is a Predicted Failure
OpenAI has a habit of hiding Easter eggs in its model announcements, and a closer look at the GPT‑4.5 launch reveals some of these hidden hints:
• “number of GPUs for GPT‑6 training”
Training GPT‑6 will require an enormous number of GPUs, which implies significant cost and technical limitations.
• “internet token count estimate”
The available data on the internet is dwindling, suggesting that there may soon be insufficient data for training models.
• “how big is the human brain”
This hint illustrates how difficult it is to mimic the complexity of the human brain relative to its size, highlighting how simplistic current AI models are by comparison. For reference, the human brain is an astonishing biological organ that performs complex thought and learning on minimal energy (around 20 watts). It learns through social interactions, education, and other means, without relying solely on massive amounts of data and computing power.
• “is deep learning hitting a wall”
This poses a fundamental question about the limits of deep learning itself and implies that a new breakthrough is needed.
Collectively, these hints suggest that OpenAI is already aware of the limits of scaling laws and that, in developing GPT‑6, they will likely focus on a different scaling paradigm. The tenfold increase in pre-training computing observed in GPT‑4.5 essentially reveals that it does not represent “effective computing.”
Former OpenAI Chief Research Officer Bob McGrew, who recently left the company, stated, “By 2025, pre-training will no longer be the optimal area for computing expenditure. The most fruitful area will be inference.” In other words, while increasing the base model size through pre-training—as seen with GPT‑4.5—requires a tenfold investment in computing power for just one incremental improvement in intelligence, far greater gains can be achieved through more focused reinforcement learning and enhanced chain-of-thought processes before output generation.
Thus, the shortcomings of GPT‑4.5 can be interpreted within the broader context of the limits of scaling laws and the need for next-generation reasoning model development. The fact that merely increasing model size cannot achieve true intelligence is demonstrated by what many consider the predicted failure of GPT‑4.5. Another OpenAI employee publicly emphasized that GPT‑4.5 signifies “the end of an era” and that “extended test time or inference computing is the only way forward.”
Leading AI teams—including OpenAI—are each pushing for higher intelligence, but it is now clear that we have entered a “phase zero” period. To reach greater heights, more computing must be allocated not only to pre-training but also to post-training and inference. Sam Altman mentioned that the high cost of GPT‑4.5 is partly due to difficulties in meeting GPU demand, and OpenAI plans, through its Stargate Project, to install 64,000 of Nvidia’s GB200 superchips (estimated at around $80,000 each) in a new data center by 2026, with 16,000 chips scheduled for installation this summer.
Nevertheless, it is important to note that GPT‑4.5 is certainly better than GPT‑4o. Although the improvements may seem subtle, the data generated by GPT‑4.5 can bring about significant enhancements when used for reinforcement learning in future reasoning model series. Its subtle EQ improvements suggest that future OpenAI models will excel in areas such as creative writing and human‑AI communication.
GPT-4.5 is by no means OpenAI’s flagship model. Tying its value to a “subtle EQ gap” that only sophisticated users (high-tasters) can appreciate was ultimately a form of showmanship aimed at conveying the message that they are a team with premium intelligence. This is directly linked to OpenAI’s differentiation strategy amid fierce AI competition. In a scenario where a clear technological edge has diminished, emphasizing emotional and creative attributes is seen as a strategy to set themselves apart from competitors (such as xAI, DeepSeek, etc.).
Above all, it is highly likely that OpenAI never intended to deploy this model on a large scale. GPT-4.5 is an enormous model that essentially serves as a “synthetic data factory” for developing the next generation of intelligence—that is, its purpose is to generate synthetic data for training inference models like o4 and GPT-6. The expensive API pricing is precisely for this reason. In other words, it’s a message of “don’t expect to apply this model for anything else.”
Previously, GPT-4 functioned as a synthetic data factory for everyone. Whether it was DeepSeek or xAI, all AI teams extracted knowledge from GPT-4 to build their own models. At this point, however, OpenAI is unlikely to let such a situation happen again. The reason OpenAI has set the API price for GPT-4.5 so high is to prevent other companies from using it to train their own models.
In conclusion, OpenAI will no longer focus solely on developing models for general users, but will invest more resources into generating data for AI model training. It should be noted that creating high-quality synthetic data alone takes more than three months. If the competition to secure higher intelligence continues, there will be little room for a slowdown in investments.