
2025 Semiconductor Market Outlook
From Training to Inference: Decoding the Next Wave of AI Hardware Growth

Before diving into the main discussion, please note that this report is not intended as investment advice and should only be used for reference.
The year 2024 was nothing short of tumultuous.
The colossal empires of Intel and Samsung crumbled, while the giant NVIDIA soared to new heights, driving significant gains in the Nasdaq.
However, in the latter half of the year, an unusual phenomenon occurred: NVIDIA’s stock began to underperform, and its valuation was surpassed by others.
As you may already know, this shift was largely driven by custom semiconductor companies, led by Broadcom.
Among the major players, Marvell Technology and Broadcom saw sharp price increases, surging 23% and 24% respectively the day after their December earnings announcements, where they delivered aggressive forecasts for custom semiconductors.
Could Broadcom become the next NVIDIA? And has NVIDIA lost its ability to lead the stock market? Let’s delve into these questions.
As many have pointed out, I predict that the era of inference will usher in the age of ASICs. With applications becoming further segmented, it will suffice to deliver the highest performance tailored to specific purposes. This marks the beginning of a renewed pursuit for the optimal semiconductors.
Gartner projects the AI custom semiconductor market to grow at a compound annual growth rate (CAGR) of 49% from 2023 to 2027, reaching $10.6 billion by 2027. While the absolute market size remains smaller than the GPU market (currently at $13.7 billion), the growth potential of custom semiconductors is greater in terms of growth rate, as GPUs are expected to grow at a CAGR of 13% over the same period.
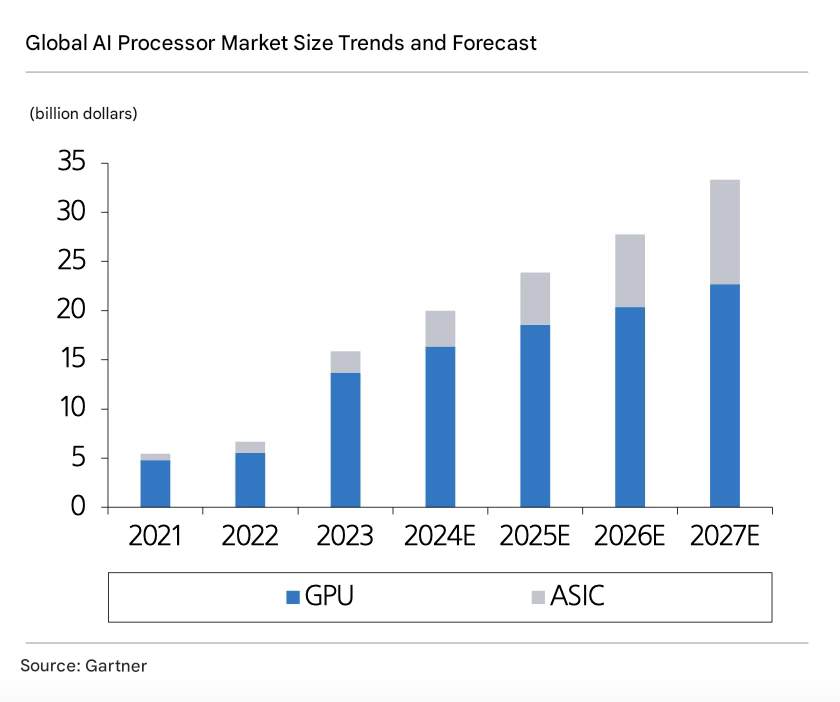
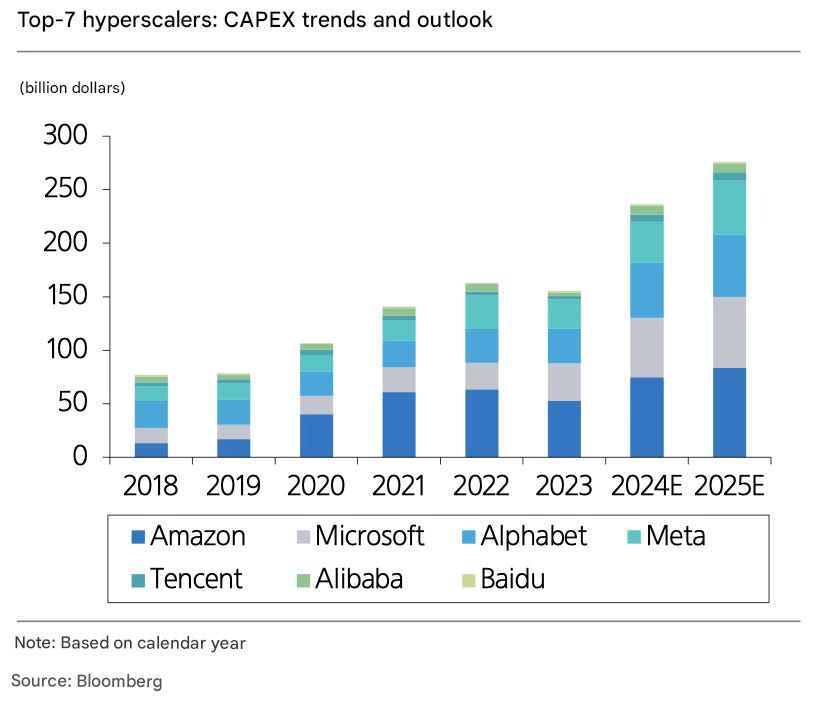
Then why is custom semiconductor gaining renewed attention now? The most important factor is that investments in AI are continuing. Nearly two years have passed since the debut of ChatGPT, yet no one is talking about reducing investments. The leading hyperscalers driving AI investments reiterated their commitment to AI during the Q3 earnings season. Across all industries, AI adoption remains the top priority for companies, making it impossible to cut investments in this area. Hyperscalers have not only raised their investment plans for this year but are also expected to further increase them next year. In fact, their CAPEX consensus has been consistently revised upward almost every quarter following earnings announcements.
What’s most important to remember is that these are the biggest tech companies in the world, generating immense profits. Would they feel financial strain from significantly increasing their investments? Amazon, Microsoft, and Alphabet, the companies with the largest CAPEX expenditures, are all spending less than 20% of their revenue on CAPEX. While direct comparisons are difficult, semiconductor manufacturers, for example, often spend well over 30% of their revenue on CAPEX. Moreover, when there is sufficient incentive to invest, as with AI, these companies have ample capacity to further increase their investment budgets.
The Rising Status of Custom Semiconductors
In the past, the importance of custom semiconductors for most hyperscalers operating cloud businesses was more focused on cost rather than performance. Their custom semiconductor-based instances were offered at lower prices compared to GPU-based instances, allowing customers to save costs. However, since GPUs are far more versatile semiconductors, it was widely accepted that cloud providers’ customers would prefer NVIDIA GPU-based cloud instances, even if it meant spending more. For instance, OpenAI itself relied on NVIDIA GPUs rather than Microsoft’s AI GPU Maia-based services.
Is It Now About Performance?
Looking at the AI events hosted by hyperscalers this year, a common theme emerges: their newly unveiled AI models were all developed using their own custom semiconductors. For example, Google emphasized that its next-generation model, Gemini 2.0, is the result of its full-stack approach, which encompasses both software and hardware. Google also highlighted that the training and inference processes of Gemini 2.0 are fully accelerated by its custom semiconductor, TPU v6 Trillium.
Even Amazon, which has been relatively quiet on AI compared to its peers, followed suit. At AWS re:Invent 2024, Amazon unveiled its multimodal model, Nova, and announced that it, too, was built using its custom semiconductors, Trainium and Inferentia.
Growing Adoption by External Customers
Another noteworthy point is the increasing number of external customers utilizing these custom semiconductors. For example, Apple recently disclosed at AWS re:Invent 2024 that it is currently using Trainium. This is particularly surprising given that Apple is typically reluctant to mention its partners and is known to be working on its own AI chip project, ACDC (Apple Chips in Data Centers).
Similarly, Anthropic, an AI startup founded by former OpenAI employees, has chosen to partner with Amazon, utilizing Amazon’s custom semiconductor-based instances, in contrast to OpenAI’s relationship with Microsoft.
OpenAI’s Innovation: The O1 Model and the Scaling of Inference
The O1 model unveiled by OpenAI represents a groundbreaking innovation distinct from the GPT series. It goes beyond mere performance improvement, demonstrating the potential to overcome previously assumed limitations. Until now, AI models were considered to perform only within the boundaries of their pre-trained knowledge, unable to solve problems beyond their training. This limitation was akin to expecting someone who had just learned basic arithmetic to suddenly solve advanced calculus.
However, the O1 model breaks through this barrier. It has proven that the more time a model spends reasoning, the better it becomes at solving complex problems. This advancement allowed O1 to surpass the capabilities of GPT-4O, showing significant improvement in fields like mathematics, coding, and even PhD-level scientific problems. According to OpenAI, the O1 model achieved over a 20 percentage-point performance boost compared to GPT-4O across various benchmarks, with improvements ranging from a minimum of 4 percentage points to a maximum of 30 percentage points depending on the specific metric.
Two Key Implications of O1’s Performance Advancement
1. The Evolution of Scaling Laws
Traditionally, AI performance improvements relied heavily on training with massive datasets. However, as the performance gains from additional data began to plateau, concerns arose about the diminishing returns of this approach. Some critics predicted a slowdown or contraction in the AI semiconductor market due to this limitation. O1, however, has demonstrated that it is possible to surpass the performance ceiling of pre-trained models. This suggests the emergence of a new scaling law focused on inference time (inference time scaling/test time scaling), signaling a shift from a training-centric paradigm to one that prioritizes inference.
2. Rapidly Growing Demand for Inference
The realization of inference-based scaling laws is likely to prompt companies to significantly expand their investment in computing resources to enhance inference performance. As a result, the demand for computing resources during the inference process could rise faster and more significantly than anticipated. This indicates that the growth cycle of the semiconductor market may be extended, with a sharp increase in demand for AI hardware.
The pessimistic outlook that “GPU demand will plummet once the training phase ends and the era of inference begins” has been invalidated by the O1 model. AI hardware, including NVIDIA GPUs, will remain indispensable not only for training but also for inference processes, creating new opportunities across the AI ecosystem.
When Inference Arrives, So Does the Promised Day
I believe that as the inference market matures, the demand for custom semiconductors will increase significantly. The primary reason for this is cost. The fundamental difference between training and inference lies in frequency. While training typically occurs only once or twice a year, inference operates in real-time, processing computations for every query. Even if the computational power required per operation differs, inference demands significantly more operations over a given period, inevitably leading to higher costs.
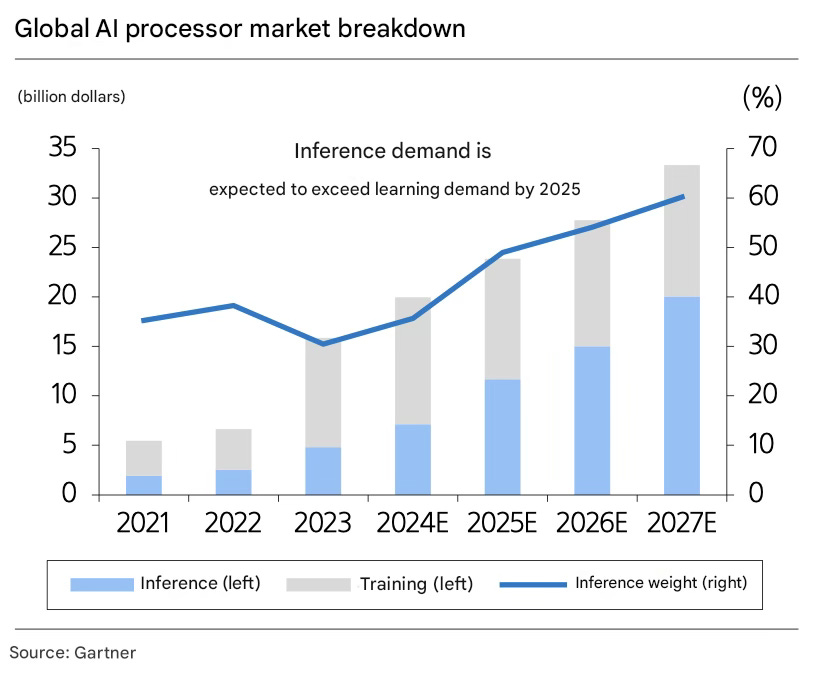
Gartner estimates that by 2025, the demand for inference will surpass that of training. By 2027, inference is projected to account for 60% of total AI semiconductor demand. From 2023 to 2027, the compound annual growth rates (CAGR) for training and inference semiconductors are estimated at 5% and 43%, respectively. While the training market will continue to grow, the inference market is expected to expand 1.5 times faster.
The sheer scale of the market alone provides ample motivation to seek alternatives to GPUs. Although the GPU market for inference will continue to grow as the inference market remains in its early stages, the growth rate of custom semiconductors for inference is expected to far outpace that of GPUs (2023–2027E inference GPU CAGR: +34% vs. inference custom semiconductor CAGR: +58%).
This is why I believe the next significant upside in the AI semiconductor industry will come from inference.
So, which stocks should I buy?
The Shift to Custom Semiconductors: Broadcom and Marvell Take the Lead
I believe market interest within the global semiconductor sector is steadily shifting toward the custom semiconductor value chain. Hyperscalers are accelerating their development of custom semiconductors, and as the era of inference approaches, growth could surpass current market expectations.
Broadcom and Marvell warrant close attention. Broadcom, already the leading provider for Google’s TPU demand, has also been reported to secure contracts with OpenAI and Apple. In a recent earnings announcement, the company revealed that it had won custom semiconductor projects from two new hyperscalers, solidifying its position as the leader in the custom semiconductor market.
Marvell serves as an alternative with a business portfolio similar to Broadcom’s. Its investment points overlap to some extent. Starting this year, Marvell is expected to see AI-related revenue growth with the mass production of custom semiconductors for Amazon. Both Broadcom and Marvell are also the top two players in the Ethernet networking chip market, offering additional upside as Ethernet adoption in AI data centers becomes inevitable.
NVIDIA: A Crisis, Yet Still the AI Powerhouse
The transition of customers to custom semiconductors poses a risk to existing semiconductor companies. Many of the custom semiconductor projects currently under development aim to replace NVIDIA GPUs, making this a potential crisis for NVIDIA.
However, excessive pessimism should be avoided. If I had to choose the top AI leader for next year, it would still be NVIDIA. Its GPUs remain the standard for AI training, and their versatility will likely ensure their continued relevance even in the era of inference. Just as cloud providers wish to avoid dependence on NVIDIA GPUs, their customers will also be reluctant to rely solely on specific cloud providers and their custom semiconductors. Moreover, NVIDIA itself could enter the custom semiconductor market. With strong semiconductor IP, design capabilities, and a robust software lineup, the company is well-positioned for this shift.
A Neutral Position: TSMC
If predicting the long-term dominance of NVIDIA or custom semiconductors seems too uncertain, TSMC offers a more stable alternative. TSMC currently produces all the latest AI semiconductors, whether NVIDIA GPUs or Google TPUs. For those content with simply riding the growth of the AI semiconductor market, TSMC is the go-to choice.
I anticipate that TSMC will remain the dominant force in the foundry market this year. The growth of the foundry market is essentially synonymous with TSMC’s growth.
It’s also worth noting that competing foundries still lag behind TSMC in yield rates. According to my latest research, Samsung Foundry’s 3nm yield rate is over 40%, significantly lower than TSMC’s 70%. (As of July 2024, Samsung’s 3nm yield rate was between 20% and 30%.)
Samsung Foundry’s breakeven point (BEP) for 3nm production requires a yield rate of around 60%. While Samsung is expected to reduce its losses this year, it is unlikely to achieve substantial profits in the near term.
What about SK Hynix?